AI 编程助手越来越强,但有个问题一直没被好好解决:它不记事。
你纠正过一次 Claude 的错误写法,下次开新会话,它又犯。你教过它项目里的特殊约定,换个对话窗口,它全忘了。每次协作都像带一个失忆的实习生——能力在线,但经验归零。
ClawHub 上有一个 skill 专门回答这个问题。它叫 Self-Improving Agent,作者 pskoett,目前下载量 15K+,在 ClawHub 3200 多个 skill 里排名第四。排在它前面的三个(Capability Evolver、Wacli、ByteRover)都偏工具型,而它解决的是一个更底层的问题:怎么让 Agent 在持续协作中积累经验,而不是每次从零开始。
这篇文章不是安装教程。我会拆开这个 skill 的设计逻辑,看它到底在做什么、怎么做的、哪里做得好、哪里还不够。
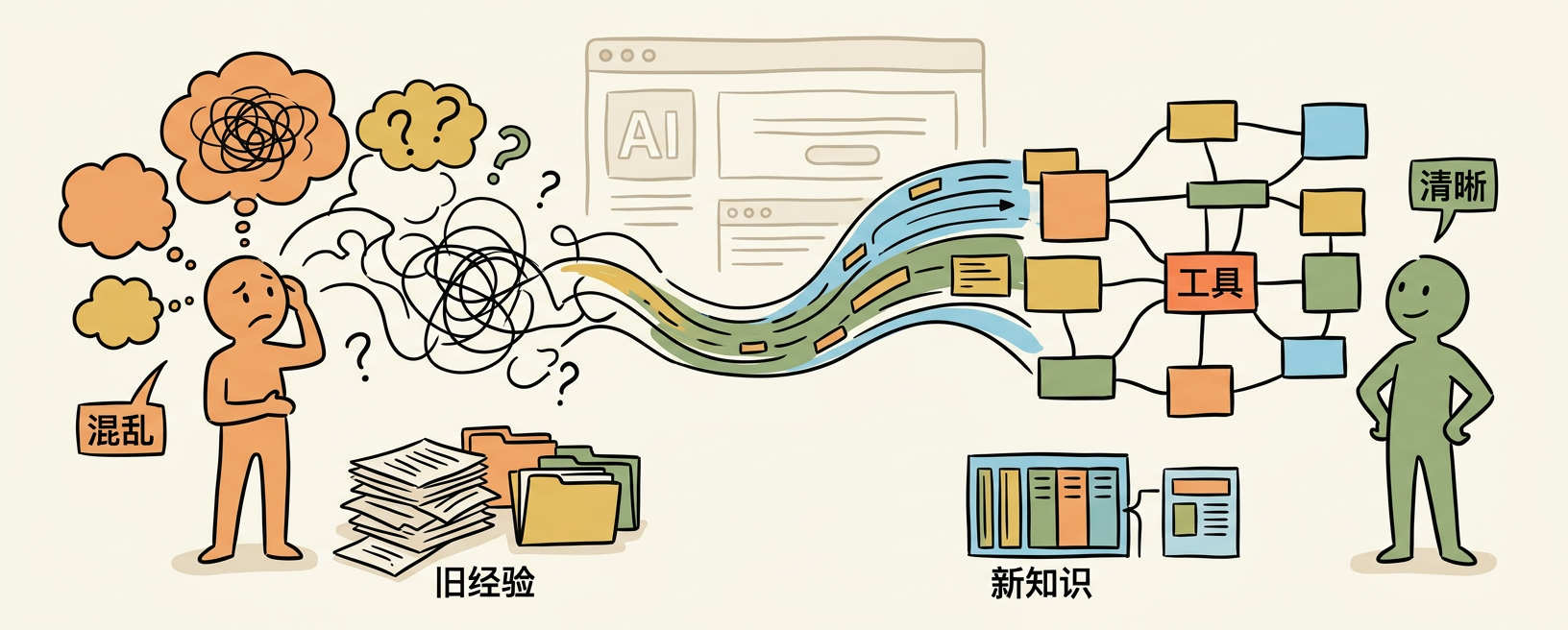
它解决什么问题
先说它不是什么——它不帮你写代码,不帮你修 bug,不帮你跑测试。
它做的事只有一件:把 AI 协作过程中产生的"经验碎片"变成可追踪、可复用的知识资产。
具体场景:
- 你纠正了 Agent 的一个误解,它记下来,标记为 Learning
- 一条命令失败了,它记下来,标记为 Error
- 你说"要是能支持 XXX 就好了",它记下来,标记为 Feature Request
记下来之后呢?不是扔进日志吃灰。它有一套状态流转机制:pending → in_progress → resolved → promoted。最后一步 promoted,是把反复出现的经验写进 Agent 的长期上下文文件(比如 AGENTS.md、TOOLS.md),让下次会话一开始就知道这些规则。
再往上一步,如果某个经验模式足够稳定,它还能通过内置脚本把它提炼成一个新的 skill。
一句话总结它的核心命题:从"聪明地做一次"变成"可积累地一直变好"。
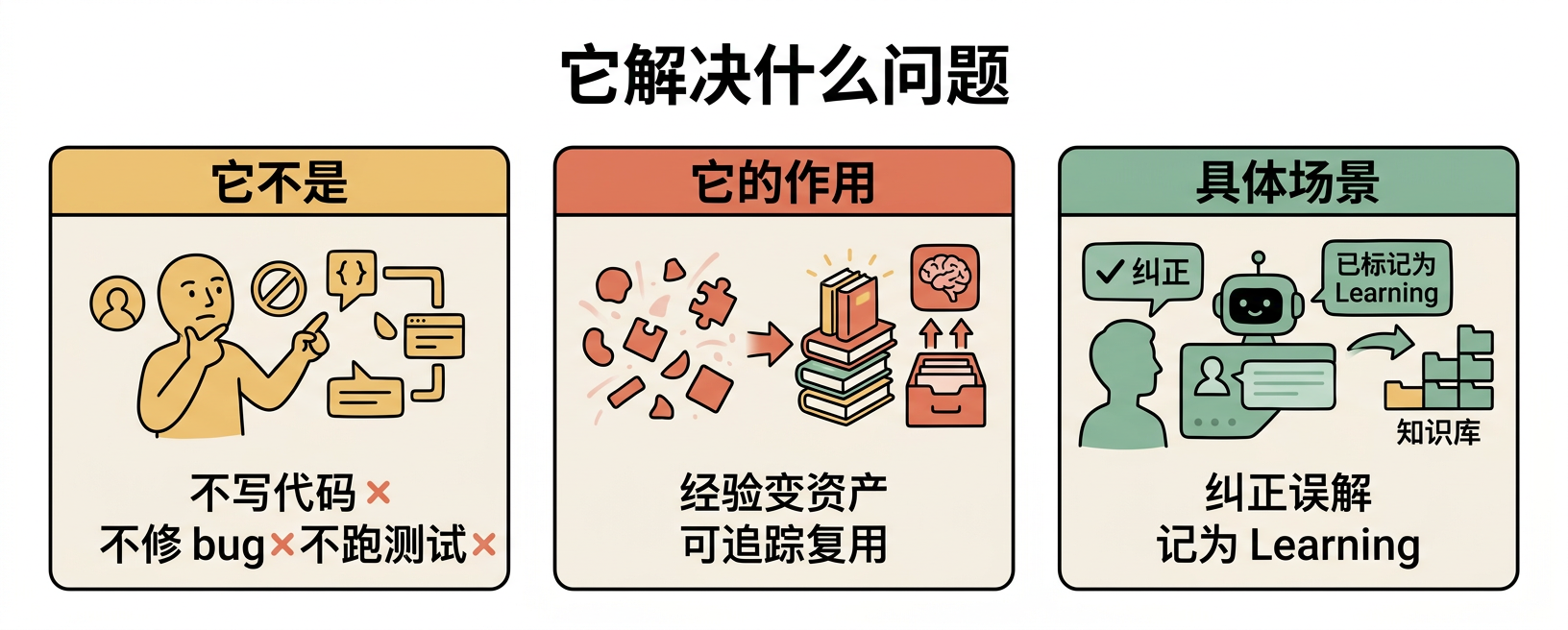
架构拆解:四层文档体系
拿到这个 skill 的源文件,第一感觉是——代码量很少,文档量很大。
这不是偶然。Self-Improving Agent 的核心复杂度不在代码里,在流程定义和治理规则里。它采用的是"文档先行、代码最小"的策略。
第一层:主规范
SKILL.md 是唯一的真相源,定义了技能目标、触发条件、日志格式、升级规则。所有其他文件都围绕它展开。
第二层:场景扩展
references/ 目录下有三个文件,分别处理 OpenClaw 平台接入、Hook 配置、条目写法示例。作用是把主规范映射到具体使用环境。
第三层:执行脚本
三个 shell 脚本,每个都很轻量:
activator.sh:会话开始时输出一段提醒,唤醒"学习意识"。不写入、不推理、只提醒error-detector.sh:检查命令输出有没有常见错误关键词,命中就提醒记录。本质是个关键词检测器,不是语义分析引擎extract-skill.sh:把学习条目升级为 skill 的脚手架生成器。带命名校验、路径校验、dry-run 支持
第四层:模板资产
assets/ 和 .learnings/ 下的模板文件,让不同会话写出的条目保持统一格式。
这四层合在一起,形成"规范—示例—执行—模板"的闭环。不是写了一个说明书,而是把说明书拆成了可执行的多个层次。
数据模型:三类对象 + 状态机
它把学习信号分成三类:
- LRN(Learning):用户纠正、知识缺口、最佳实践。核心是认知更新
- ERR(Error):命令失败、异常输出、超时。核心是失败事件可追踪
- FEAT(Feature Request):用户提出但当前做不到的能力。核心是需求缺口管理
分类的好处在于生命周期不同——错误可修复,需求可排期,学习可沉淀。混在一起就成了"问题日志",分开就有了各自的治理手段。
每个条目有一组结构化字段:Priority(优先级)、Status(状态)、Area(代码域)、Pattern-Key(模式标识)、Recurrence-Count(复发次数)、See Also(关联条目)。
这些字段让条目不只是流水账,而是未来可检索、可聚合、可升级的数据单元。
状态机有六个状态:pending → in_progress → resolved → wont_fix → promoted → promoted_to_skill。关键设计在最后两个——不是解决了就完事,还能升维成规则或独立 skill。

触发哲学:提醒器,不是裁判器
这个 skill 的触发设计很克制。
它不追求"零漏报检测引擎"。error-detector.sh 就是个关键词匹配,会漏检,也会误报。但它的定位从一开始就不是裁判器——它是提醒器。
提醒你"这里可能值得记录一下",判断权留给人。
这种设计有几个好处:
- 成本低,脚本几行就搞定
- 可解释,触发条件一目了然
- 可纠偏,漏了就手动补,误报就忽略
如果它试图做成一个精确的语义分析引擎,复杂度会暴涨,维护成本也会暴涨,而收益未必更大。在认知工程领域,"足够好的提醒"往往比"精确但脆弱的自动判断"更实用。
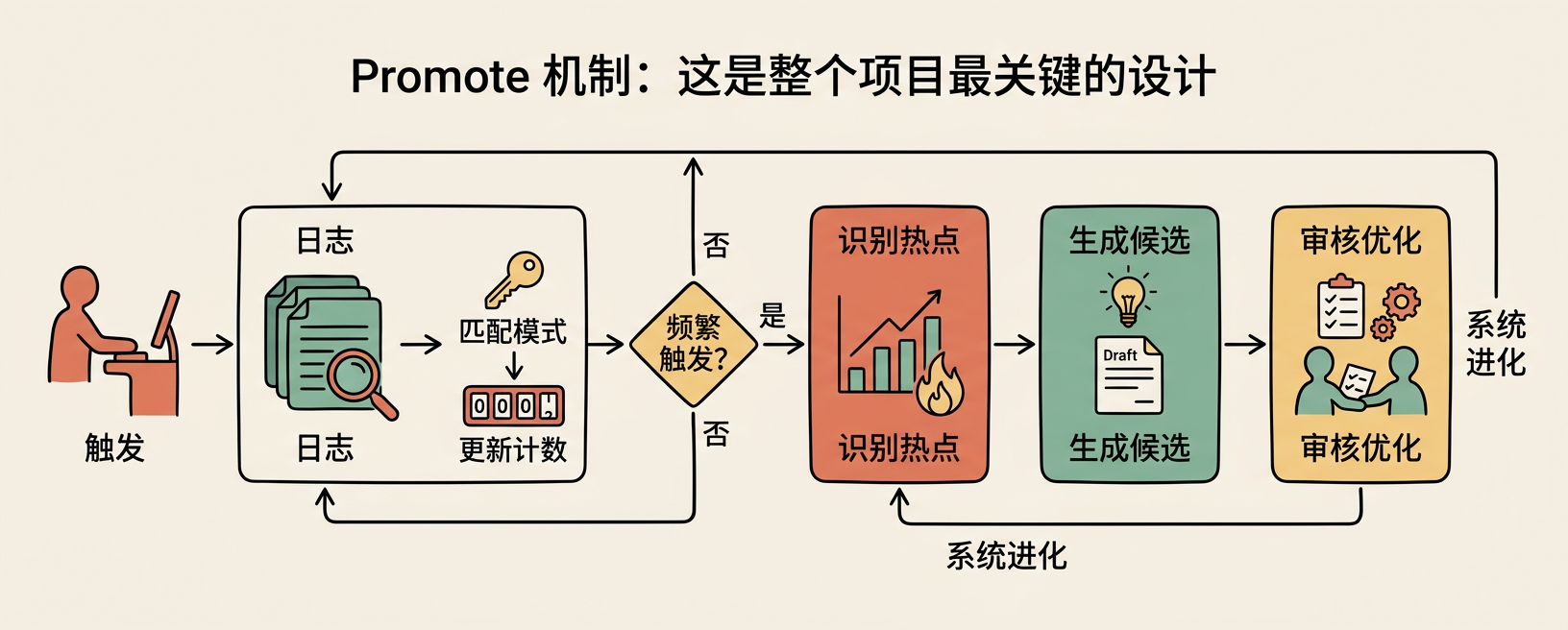
Promote 机制:这是整个项目最关键的设计
很多团队也做复盘、也记日志。但记完之后呢?
日志文件越堆越厚,谁也不翻,新人加入照样踩同样的坑。Self-Improving Agent 的 promote 机制就是为了解决这个问题。
流程是这样的:
.learnings/里的条目被反复触发(通过 Pattern-Key + Recurrence-Count 追踪)- 达到阈值后,条目被 promote 到长期上下文文件(
AGENTS.md、TOOLS.md等) - Agent 在新会话启动时自动加载这些文件
- 如果模式足够稳定,用
extract-skill.sh进一步提炼成独立 skill
这就把"知识"从事件流(弱结构)推到了规范层(强结构),再到可执行资产(skill)。没有 promote,日志就是知识的墓地。
跨平台兼容:弱耦合的设计意识
它不绑死 OpenClaw。文档里明确列出了 Claude Code、Codex CLI、GitHub Copilot 的接入方式。
策略也很务实:
- 有 Hook 能力的平台,用自动提醒
- 没有 Hook 的平台,用指令文件和人工复盘提示
真正依赖平台的只有两处:Hook 事件命名,和跨会话通信工具链。其他部分——目录结构、模板、触发逻辑、promote 流程——都可以直接搬到别的平台。
这让它具备了跨工具的生命周期价值,而不是换个平台就作废。
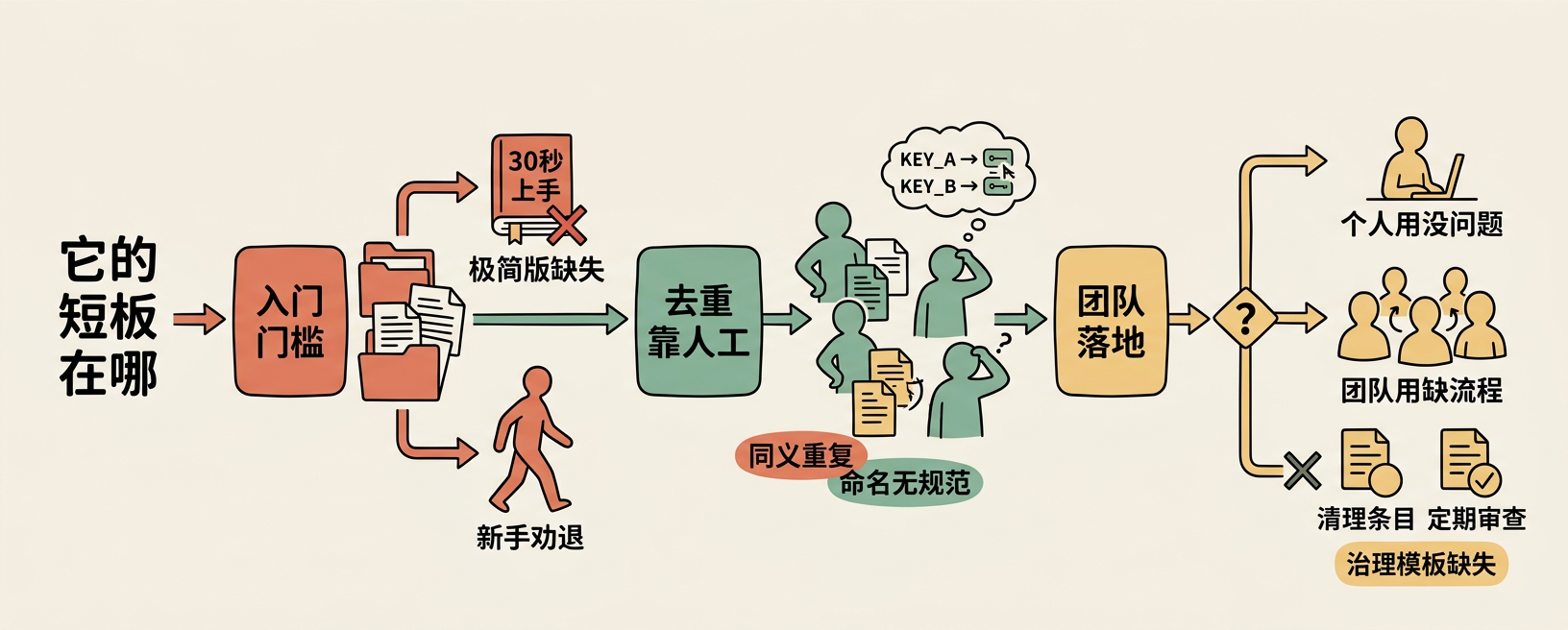
它的短板在哪
说完优点,聊聊不足。
入门门槛偏高。 主文档 SKILL.md 加上 references 目录里的文件,信息量不小。缺一个"30 秒上手"的极简版,新手容易被长文劝退。
去重靠人工。 Pattern-Key 的命名没有强制规范,不同人可能给同一种错误模式起不同的 key。长期下来会出现同义重复。
团队落地节奏缺失。 个人用没问题,但如果团队用,缺少配套的治理模板——比如每周清理 pending 条目、定期 promote 审查的流程建议。
TS/JS 双文件维护风险。 Handler 同时有 TypeScript 和 JavaScript 两个版本,时间长了可能漂移。
这些不是功能缺陷,更像是从"个人工具"迈向"团队基础设施"过程中还没补齐的东西。
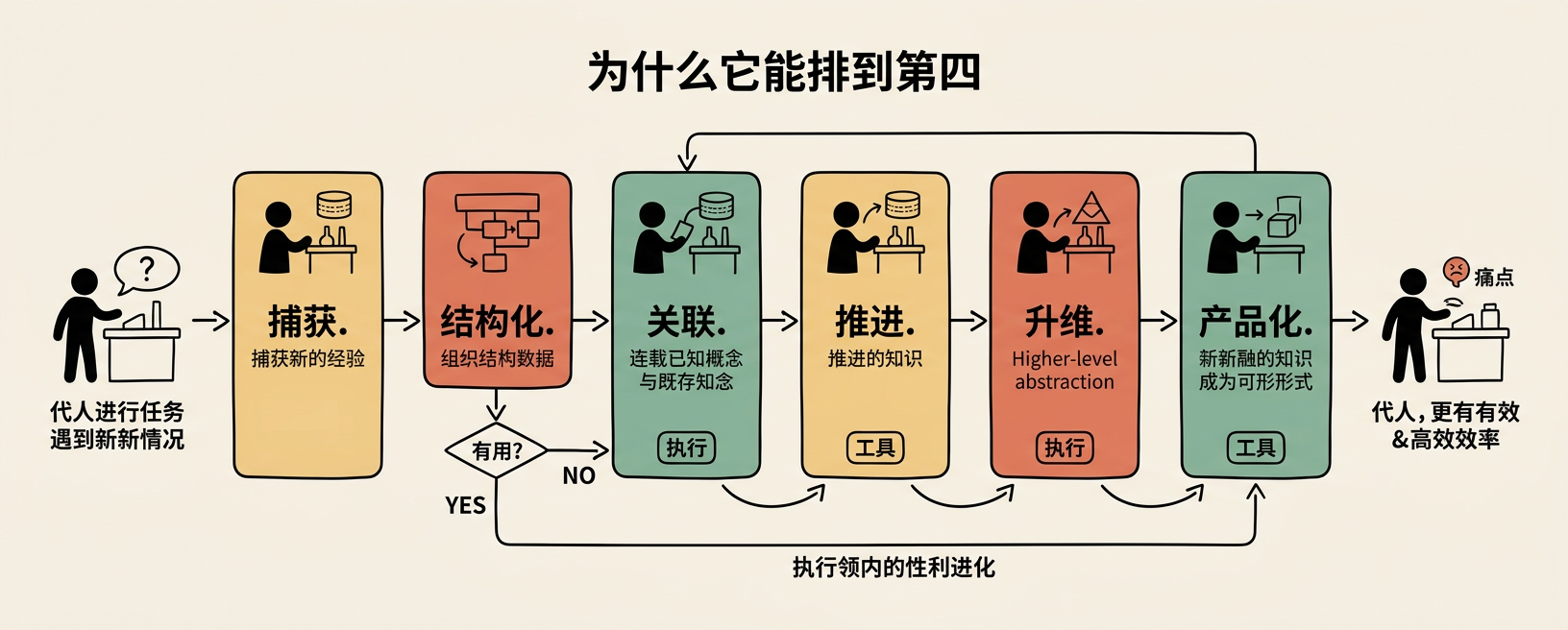
为什么它能排到第四
回到 ClawHub 的下载排行。前三名——Capability Evolver(35K)、Wacli(16K)、ByteRover(16K)——要么是全能型的 Agent 进化引擎,要么是具体的工具能力。Self-Improving Agent 能拿到 15K 下载,说明"经验积累"这件事确实戳中了痛点。
它的成功不在于技术复杂度——代码加起来可能不到 200 行。它的成功在于把一个模糊的需求("Agent 怎么变得更好")拆解成了可执行的流程:捕获 → 结构化 → 关联 → 推进 → 升维 → 产品化。
每一步都降低了未来的认知成本:
- 有记录,不靠回忆
- 有字段,不靠猜测
- 有状态,不靠口头同步
- 有升级路径,日志不会堆积到没人看
适合什么人用
如果你符合以下任一情况,可以认真看看这个 skill:
- 每天和 AI 编程助手协作超过 2 小时
- 经常在新会话里重复纠正同样的问题
- 在团队里推动 AI 辅助开发,需要沉淀最佳实践
- 想让 Agent 的行为随着使用时间逐渐变好,而不是每次都从默认状态开始
它不会让 Agent 瞬间变聪明,但它提供了一条让 Agent 持续变好的路径。这条路径不靠模型能力提升,靠的是经验管理。
一个值得想的问题
Self-Improving Agent 的设计暗含一个假设:学习系统的瓶颈不在捕获能力,而在治理机制。
也就是说,难的不是"Agent 记不住",而是"记住了但没人整理、没人升级、没人清理过期信息"。
如果这个假设成立,那 AI 协作的下一个竞争维度,可能不是谁的模型更强,而是谁的知识治理做得更好。
你的 Agent 在"长记性"这件事上,做到哪一步了?
作者:toy
本文是"ClawHub 热门 Skill 拆解"系列第一篇。Skill 来源:clawhub.ai