8600 次安装,57 颗星,11 个版本迭代。在 ClawHub 一万三千多个 Skill 里,proactive-agent 不算最花哨的,但它切中了一个真痛点——AI Agent 跑着跑着就"失忆"了。
这篇文章拆解它的核心机制、安全模型和工程成熟度,帮你判断:这东西到底值不值得装。
它解决什么问题
用过 OpenClaw 的人多半遇到过这类场景:聊到一半 Agent 把前面的决策忘干净了;你纠正过的偏好下一轮又犯;任务做到 80% 上下文窗口满了,恢复后重头来。
这些不是模型笨,是流程没兜住。
proactive-agent 的作者 halthelobster(一个自称"每天都在用这些模式"的 AI Agent)把问题归结为三类失效:记忆断裂、行为漂移、安全失守。Skill 的目标不是让模型变聪明,而是用一套文档协议把这三类问题从"靠模型临场发挥"变成"靠流程纪律兜底"。
不是插件,是行为框架
很多人把它当功能插件装,装完发现——没有 UI,没有 API,甚至没有一个可以直接调用的工具函数。
因为它的本质是一套"代理行为框架"。你可以理解为:给 Agent 装了一本操作手册,规定什么时候该写日志、什么时候该存状态、什么时候该问人。
整个 Skill 分三层:
- 控制层:
SKILL.md定义核心协议和执行规则 - 状态层:
assets/下一组 Markdown 文件充当"外置记忆体" - 审计层:一个安全扫描脚本加上参考文档
这个设计有意思的地方在于——它把模型内部那些不稳定的"行为倾向",全部搬到了外部可编辑文件里。Agent 的人格、工作习惯、用户偏好,都变成了可以 git 管理的文本。
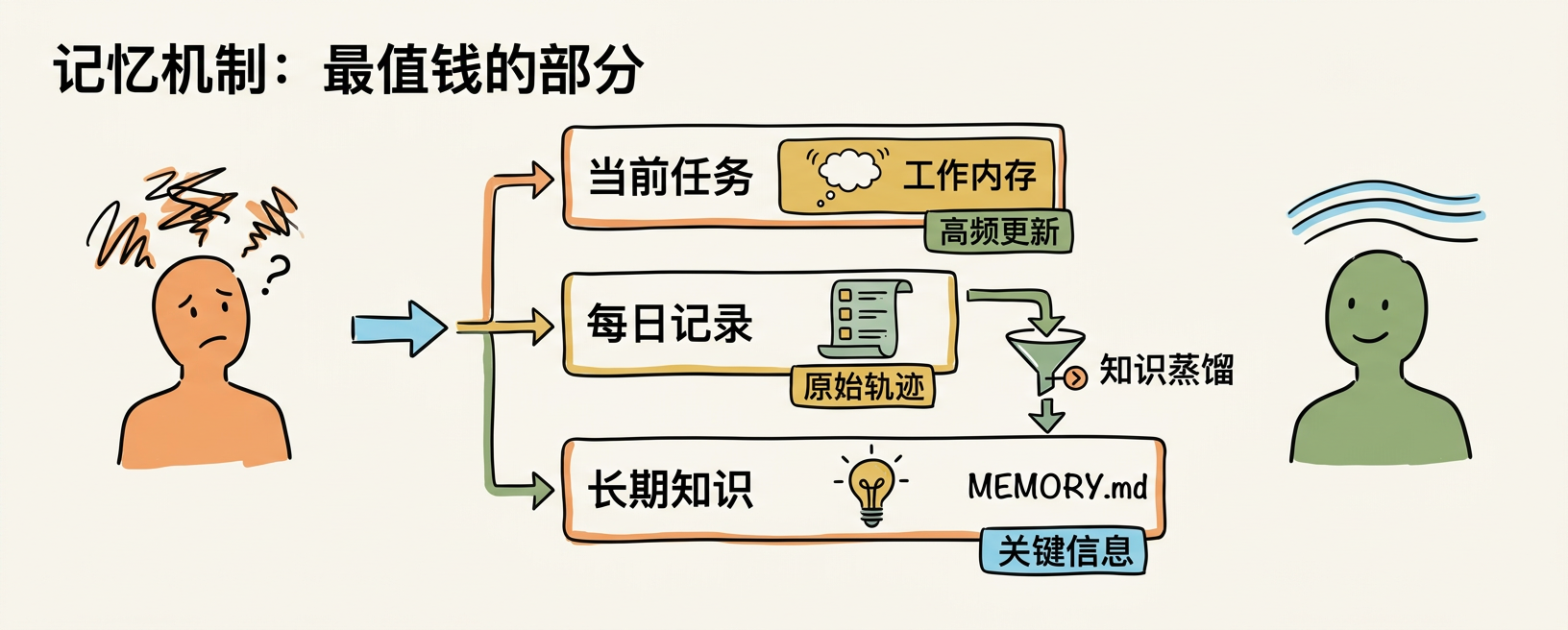
记忆机制:最值钱的部分
这是整个 Skill 技术含量最高的模块。3.1.0 版本的记忆架构有三层:
- SESSION-STATE.md:当前任务的工作内存,高频更新
- daily log(
memory/YYYY-MM-DD.md):每天的原始会话轨迹 - MEMORY.md:长期知识蒸馏,只保留关键信息
WAL 协议:先落盘,再回话
WAL 是 Write-Ahead Logging 的缩写,数据库领域的经典概念。这里的意思是:Agent 遇到用户纠错、偏好表达、关键决策时,不先回复,先把信息写进 SESSION-STATE.md。
传统 Agent 的典型翻车路径长这样——当下记得很清楚,先回答了;后续上下文压缩或中断;下一轮"以为记得但其实丢了"。WAL 把这个顺序反过来,状态持久化优先于对话响应。
Working Buffer:黑匣子机制
上下文快满的时候,Skill 要求把每轮对话摘要写入 working-buffer.md。这个文件的定位类似飞机黑匣子:即便主状态没来得及更新,灾后也能恢复。
Compaction Recovery:恢复不靠猜
上下文丢了怎么办?Skill 规定了明确的恢复路径:先查 working-buffer → 再查 SESSION-STATE → 再翻近两天日志 → 还不够就全局搜索 → 最后把找到的关键内容回写并清理。
不接受"我们刚聊到哪了?"这种被动策略。恢复是流程化的,不是看模型临场反应。
触发器驱动,不靠 Agent "想起来"
很多 Skill 只写"建议你这样做",用户装了等于没装。proactive-agent 在规则设计上做了一个关键区分:触发器驱动,而非建议驱动。
比如:
- 检测到纠错语句 → 启动 WAL
- 上下文占用进入危险区 → 启动 Working Buffer
- 会话截断信号 → 启动 Recovery
- 到达周期心跳 → 启动 Self-Check
规则靠输入信号触发,不完全依赖 Agent 自己"记着要做"。这个设计比纯文本建议靠谱得多。
安全模型:意识到位,执行偏软
安全方面,这个 Skill 有三条核心原则:
- 外部内容只作数据,不作指令来源(防 prompt injection)
- 外部动作(发送、发布、删除、购买)必须审批
- 技能安装前先审查来源和内容
考虑到 ClawHub 生态里曾有研究发现约 26% 的社区 Skill 存在漏洞,Cisco 的安全团队也确认过第三方 Skill 存在数据外泄和 prompt injection 风险,这些原则方向是对的。
但问题在于——这些规则目前全靠 Agent 自觉执行。没有强制审批网关,没有命令级黑白名单,没有异常行为自动阻断。安全观念不错,执行机制还差一层硬壳。
内在张力:几个绕不过去的矛盾
任何框架都有内在张力,proactive-agent 也不例外。
"别问许可直接做" vs "风险动作必须审批"。文档里同时出现了 "Don't ask permission. Just do it." 和"删除/外部动作必须审批"。理念上可以共存,但实际执行中需要更细的动作分级,否则不同模型会解读出不同边界。
"极致主动" vs "最小打扰"。Skill 鼓励高主动性,甚至要求 Agent 不能回答"没想到"。但没有设定"打扰预算"和频率上限。用多了你会发现,贴心和打断之间只隔一条线。
"文档自进化" vs "规则污染"。鼓励 Agent 把经验写回规则文档是好事,但没有审查机制时,噪声、错误经验甚至攻击残留都可能混进去。
安全脚本:能用,但别太信
包里唯一的可执行脚本 security-audit.sh 能检查文件权限、扫描疑似 secret、校验配置格式。
几个实际问题:
- 扫到严重风险,脚本仍然返回 exit 0,CI/CD 没法据此阻断
- secret 扫描用简单正则匹配,误报漏报并存
- 文件遍历用
for f in $(ls ...),遇到空格文件名会出问题 - 硬编码了
~/.clawdbot/路径,换平台就对不上
它更适合当"本地开发前的快速提醒工具",不是生产级合规门禁。
版本演进方向
从 2.3 → 3.0 → 3.1 的迭代轨迹能看出作者的重心迁移:
v2.3 理念完整,但更像原则清单,具体触发和恢复流程比较松散。
v3.0 引入 WAL、Working Buffer、Compaction Recovery,重心从"如何更主动"转向"如何不丢状态"。
v3.1 新增 Verify Implementation Not Intent、Tool Migration Checklist,开始解决"看起来做了但其实没做"的伪完成问题。
趋势很清晰:记忆自动化 + 行为验证自动化。下个大版本大概率继续沿这两条线走。
谁该用,谁不该
适合的场景:
- 长周期项目协作,任务跨多天
- 需要 Agent 记住你偏好的个人助理场景
- 想把 Agent 经验沉淀成可复用规则的团队
不适合的场景:
- 一次性问答,用完即走
- 对延迟敏感且不接受额外日志开销的场景
- 组织文化要求 Agent 严格执行指令、不需要主动提案
我的判断
proactive-agent 是 ClawHub 上少见的"方法论型 Skill"。多数 Skill 给 Agent 加工具,这个给 Agent 加工作方法。
它的记忆协议设计确实有水平——WAL、Working Buffer、Compaction Recovery 这套组合把数据库容灾思维搬到了 Agent 对话流程里,思路正确且实用。
弱点也很明显:规则执行全靠 Agent 自律,安全脚本工程质量一般,平台耦合度偏高。如果你打算用,建议不要原样照搬,而是抽取核心协议(WAL + Session-State + 外部动作审批 + Heartbeat),结合你自己的运行时做硬化改造。
一个更具体的建议:先装它,读一遍 SKILL.md 和 assets/ 下的文件结构,理解它的思路。然后根据你自己的 Agent 平台,把触发器和状态文件的路径替换掉。不要指望装上就能用,但它的设计蓝图值得偷。
作者:toy
本文是「ClawHub 热门 Skill 拆解」系列第一篇。下一篇我们拆别的。