为什么要写这篇
OpenClaw 的记忆检索不是“自动发生”的。很多人看到 memory_search、memory_get 以为系统会自动帮你把历史记忆塞进上下文,实际并不是。这里按“可用 → 触发 → 执行 → 同步”的逻辑,把配置、触发条件和调用链路讲清楚。
这篇基于我自己的源码阅读笔记做整理,同时加上可操作的配置方式。
先把配置跑通(最小可用配置)
下面是我自己的默认配置示例。先确保工具“可用”,再谈触发和执行:
openclaw config set agents.defaults.memorySearch.enabled true
openclaw config set agents.defaults.memorySearch.provider openai
openclaw config set agents.defaults.memorySearch.model text-embedding-3-small
openclaw config set agents.defaults.memorySearch.sources '["memory","sessions"]'
openclaw config set agents.defaults.memorySearch.experimental.sessionMemory true
注意 provider 目前只允许这 3 个值:
openai
local
gemini
对应校验在 zod-schema.agent-runtime.ts 里,超出会直接被 schema 拒掉。
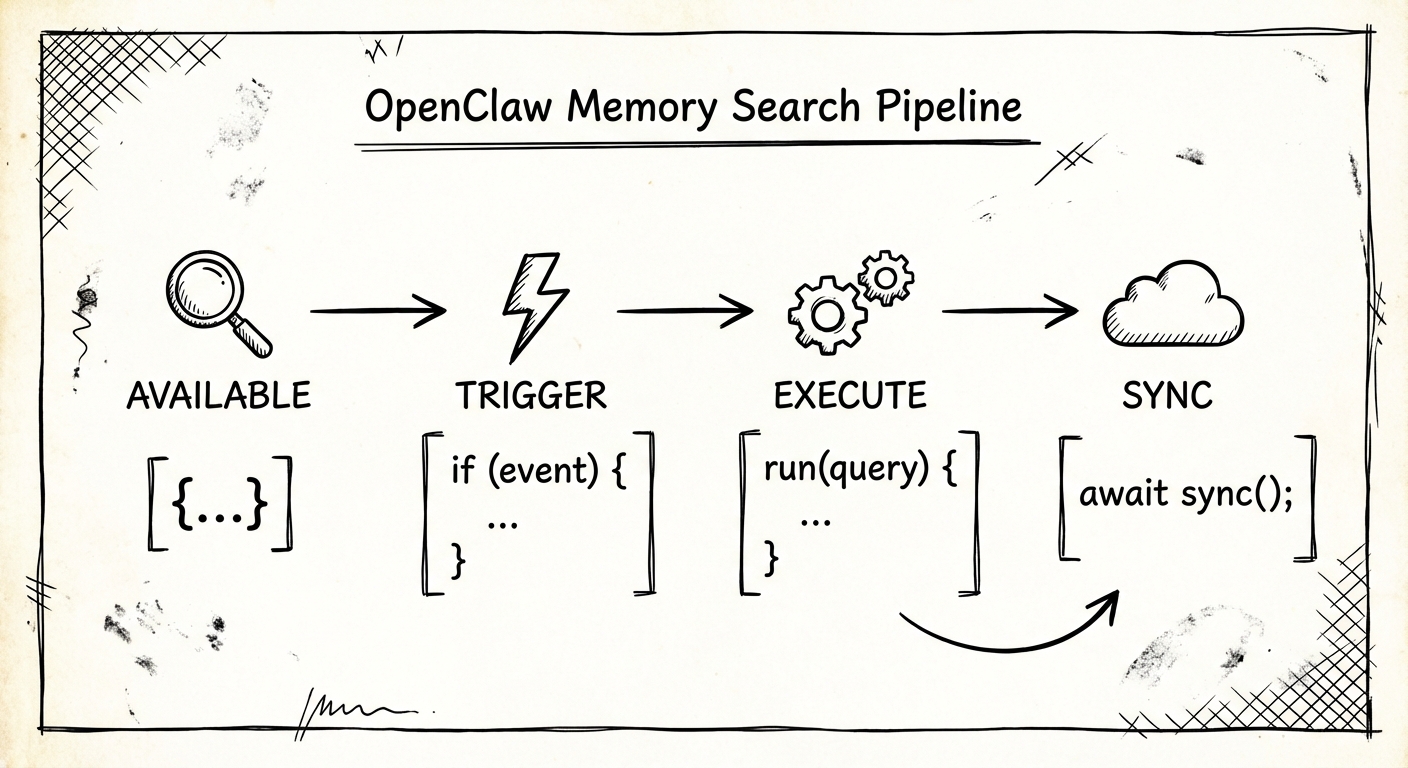
一图理解:可用 → 触发 → 执行 → 同步
你可以把链路看成四个关卡:
- 可用:工具会不会出现在可用工具列表里。
- 触发:模型会不会调用它。
- 执行:调用后到底跑了哪些函数。
- 同步:检索时索引是否刷新。
下面逐层拆。
1. 工具是否“可用”(触发前提)
工具要先“存在”,否则根本谈不上触发。
1.1 工具是否被创建
createMemorySearchTool / createMemoryGetTool 会根据配置决定是否创建工具:
- 文件:
memory-tool.ts - 条件:
config存在resolveMemorySearchConfig(cfg, agentId)返回启用配置
如果条件不满足,工具直接返回 null(即“不存在”)。
1.2 工具是否被策略允许
即便工具被创建了,也要通过工具策略过滤:
- 文件:
tool-policy.ts - 规则:
group:memory包含memory_search/memory_get codingprofile 默认允许group:memory
工具策略(profile/global/agent/group/sandbox)会决定最终的可用列表。
1.3 一个容易忽略的点
我在仓库里没有看到这两个工具被直接加入 createOpenClawCodingTools() 的列表。
当前只有 index.ts 暴露了 createMemorySearchTool/createMemoryGetTool 给插件 runtime。
如果你实际运行时能用 memory tools,说明:
- 要么别处有注册逻辑
- 要么在
@mariozechner/pi-coding-agent内部注入
建议你在 createOpenClawCodingTools() 末尾打印 tools.map(t => t.name),确认 memory_search/memory_get 是否真的被注册。对应文件是 pi-tools.ts。
2. 触发机制(谁决定调用)
触发不是系统自动执行,而是模型在 stream 中主动发起 tool call。
2.1 系统 Prompt 的“强制要求”
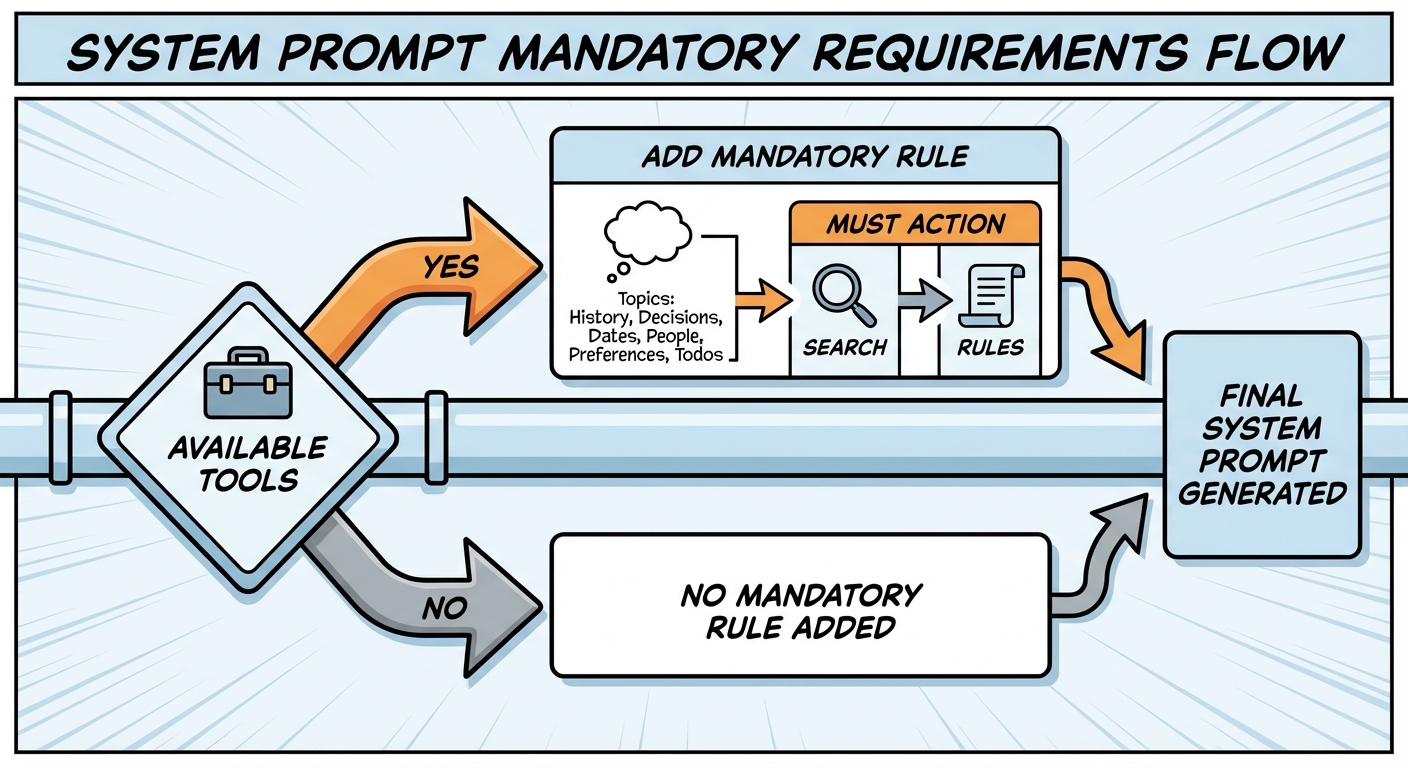
系统 prompt 只有在工具可用时才会加入强制说明:
- 文件:
system-prompt.ts - 逻辑:只有
availableTools包含memory_search或memory_get才会加这段规则:
在回答关于历史工作 / 决策 / 日期 / 人 / 偏好 / todos 之前,必须先
memory_search,再memory_get。
这句话本质是“对模型的行为约束”。它不会自动调用工具,只会影响模型在推理时生成 tool call 的决策。
2.2 触发源是谁
- 触发源是 LLM 自己
- 系统只提供规则和可用工具列表
- 用户也可以显式要求“先查记忆”来强化调用
3. 执行链路(触发后发生什么)
3.1 memory_search 执行路径
- 文件:
memory-tool.ts - 关键调用:
getMemorySearchManager({ cfg, agentId })manager.search(query, { maxResults, minScore, sessionKey })- 返回:
results- embedding provider / model / fallback 信息
3.2 memory_get 执行路径
- 同文件:
memory-tool.ts - 关键调用:
manager.readFile({ relPath, from, lines })- 返回:
- 指定文件的行级片段(snippet)
- 目的是减少上下文长度
4. “触发 search 时的索引同步”(最容易混淆)
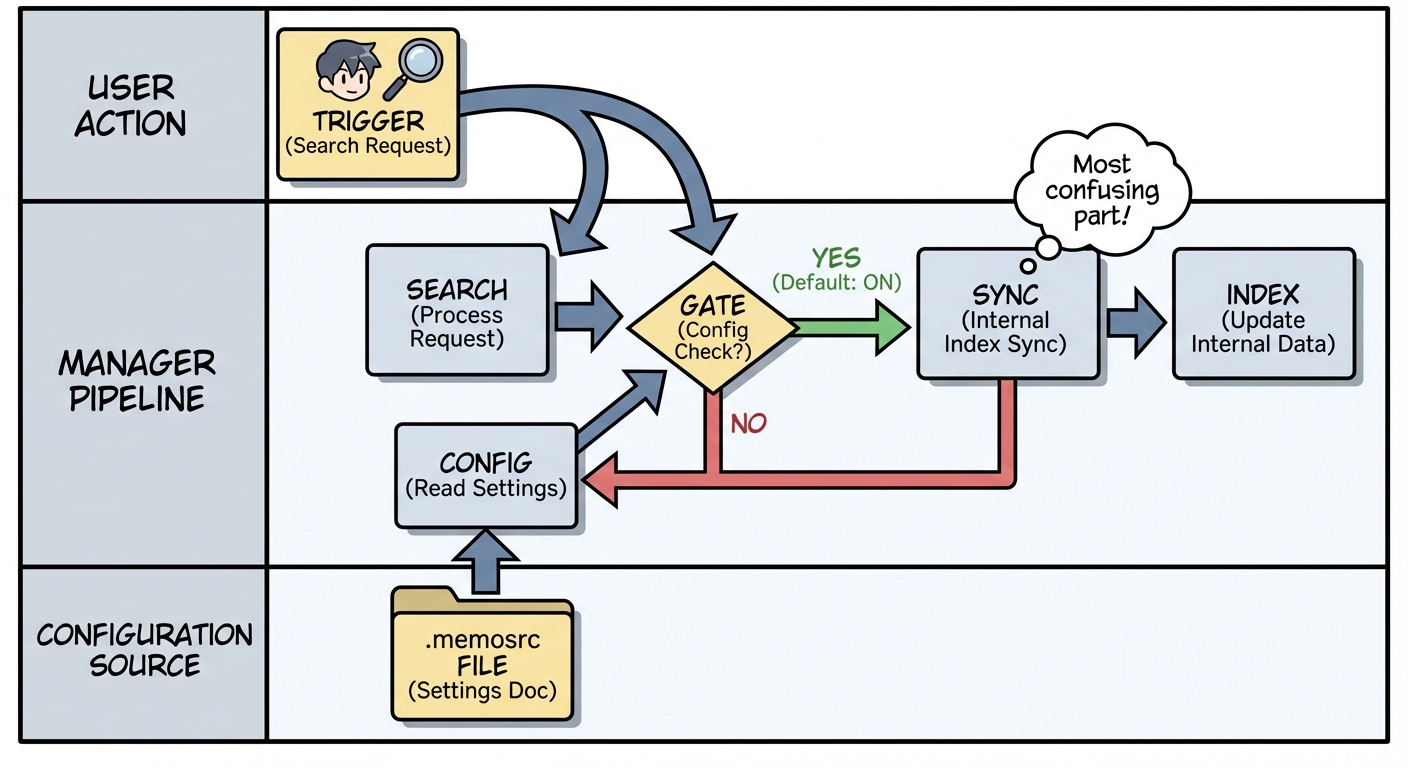
memory_search 会触发 manager 内部的索引同步(如果配置了 sync.onSearch,默认开启)。
配置来源:
resolveMemorySearchConfig- 文件:
memory-search.ts
这不是“调用 memory_search 的触发条件”,而是:
- memory_search 调用后顺带刷新索引(如果 dirty)
- 目的只是保证检索时是最新索引
很多人把“索引刷新”误以为“触发条件”。其实它发生在调用之后。
5. 一句话总结“触发机制”
memory_search / memory_get 的触发,是“工具可用 + 系统 prompt 指令 + LLM 决策”的组合结果。
系统不会自动调用它们,真正触发的是模型生成 tool call。
6. 排错清单(我自己常用)
如果你发现 memory tools 没被触发,优先检查这几项:
memorySearch.enabled是否为 true- provider 是否在允许列表(
openai / gemini / local) - tool-policy 是否过滤掉
group:memory availableTools列表里是否有memory_search/memory_getsystem-prompt.ts是否插入了强制规则
7. 一点观察
OpenClaw 没有“把记忆块自动拼进 system prompt 或每轮上下文”的机制,全部按需、Tool 驱动。
这是一种很干净的设计,行为可控,也更好调试。
就这些。