作者:toy
这篇在做什么
市面上大量"开源项目分析"文章的套路是:列代码路径 → 说"这很硬" → 结束。读完你知道了文件在哪,但不知道设计好不好、跟替代方案比如何、规模化会不会炸。
这篇不这样写。我把 waoowaoo(项目仓库:https://github.com/waoowaooAI/waoowaoo )的核心模块全拆了一遍,从三个角度给判断:
- 源码深读:每个设计决策背后的 trade-off 是什么,选了什么、放弃了什么
- CTO 视角:如果你要基于它做业务,哪些能直接用、哪些必须改
- 竞品对比:跟自建、跟 Runway/Pika API 比,它的技术护城河在哪
先说架构全貌,再说三样值得抄的,最后说三样会炸的。
架构全貌:标准 indie SaaS 技术栈
技术选型一眼看完:
- 前端 + API:Next.js(App Router + Turbopack)
- 任务队列:BullMQ(Redis 驱动)
- 数据库:Prisma + PostgreSQL
- Worker:4 个独立进程(image / video / voice / text),tsx 直接跑
- 定时巡检:单独的 watchdog 进程
- 对象存储:腾讯云 COS
- AI SDK:Vercel AI SDK + OpenRouter + Google GenAI + fal.ai
这是一个 Next.js 单体 + 独立 Worker 的架构。Web 层和 Worker 层通过 BullMQ 解耦,共享一个 PostgreSQL 数据库。没有微服务,没有消息总线,没有 K8s。
CTO 判断:这个选型在日活 1 万以下非常合理。简单、部署成本低、团队不需要运维专家。但上到日活 5 万以上会遇到瓶颈(后面具体说)。
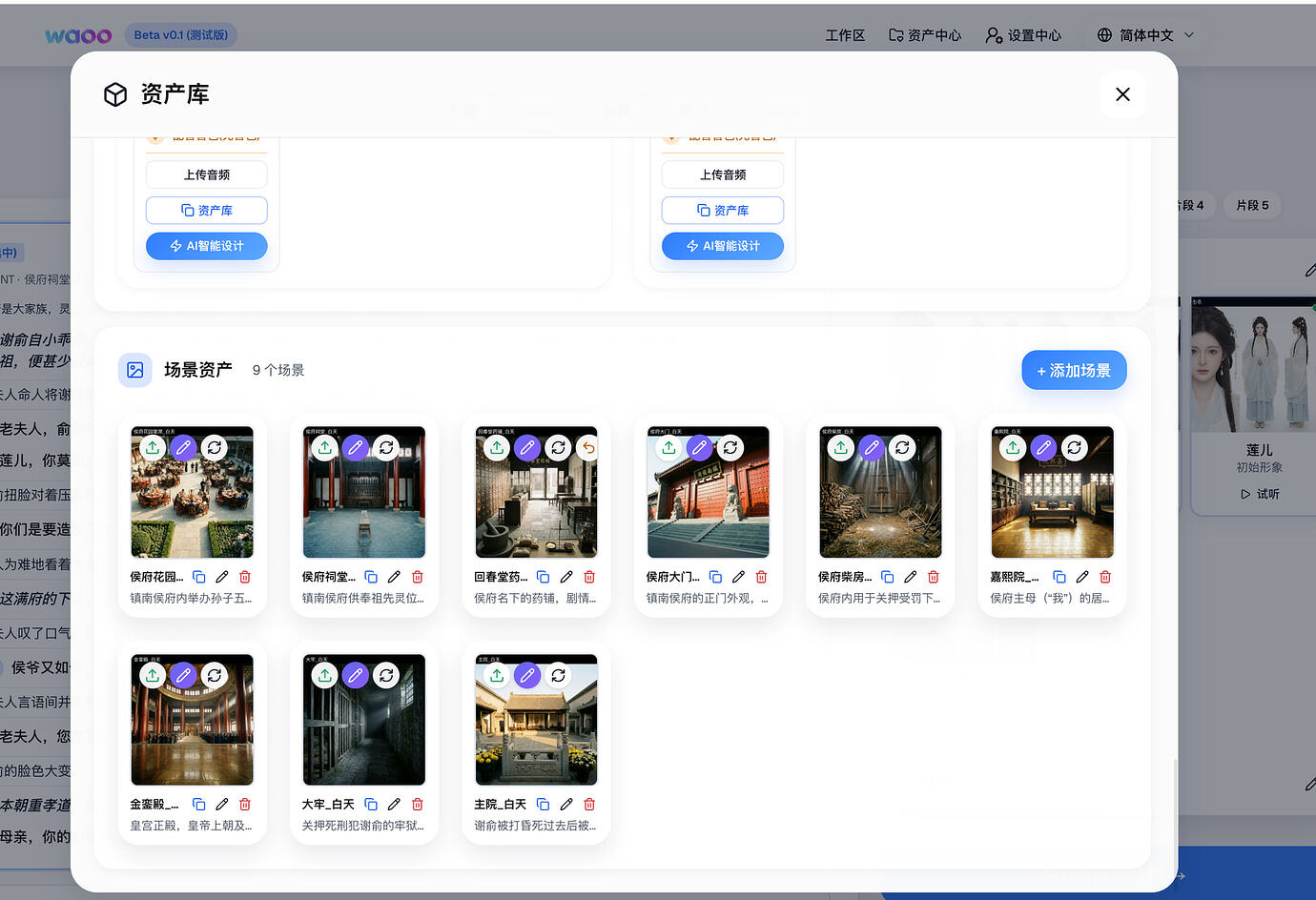
三样值得抄
一、SHADOW 计费模式——上线前先"看账本跑一周"
大多数计费系统只有两个状态:开和关。waoowaoo 做了三个:
模式
行为
用途
OFF
完全不计费,任务直接跑
开发调试
SHADOW
记账但不扣钱,把"本应扣多少"写进流水
上线前观察真实成本
ENFORCE
真实冻结、扣费、回滚
生产运行
三态切换通过环境变量 BILLING_MODE 控制。
为什么这值得抄?
因为定价永远是拍的。你觉得生成一集视频成本 2 块,上线后发现实际是 5 块——但如果已经在 ENFORCE 模式了,你要么亏钱要么改价惹怒用户。
SHADOW 模式让你在真实流量下跑一周,看到"如果开启扣费,每个用户会被扣多少",然后再调价格、再切 ENFORCE。这不是功能,是部署策略。
跟行业对比:Stripe 的 test mode 只在沙箱环境模拟,不能在生产流量上"旁听"真实成本。waoowaoo 的 SHADOW 模式可以——同样的代码、同样的流量、同样的模型调用,只是不真扣钱。这比 Stripe 的 test mode 更贴近真实。
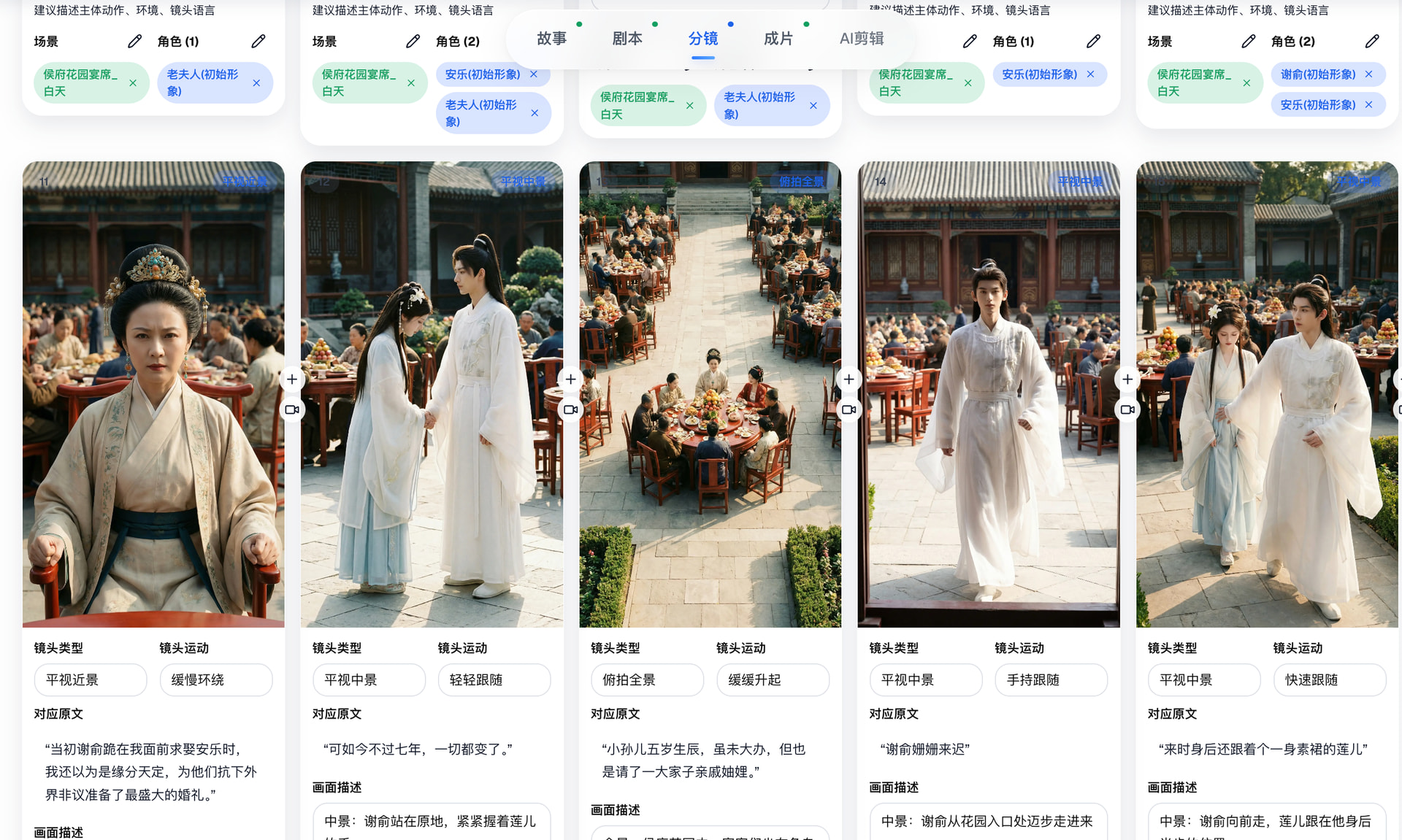
二、DB ↔ BullMQ 三层对账——解决"任务永久卡死"
任何用队列的系统都有一个问题:数据库说任务还在跑,但队列里的 Job 已经丢了。用户看到的是一个永远转圈的进度条。
BullMQ 自带 stalledInterval 可以检测 stalled jobs,但它只管队列侧。如果 DB 和队列的状态脱节了,BullMQ 不知道。
waoowaoo 做了三层对账:
第一层:创建时即时校验。 当新任务触发去重(dedupeKey 命中旧任务),不是直接返回"已存在",而是去 BullMQ 里查一下旧任务的 Job 还活不活着。如果 Job 已经死了,立刻把旧任务标记失败、回滚冻结金额、释放 dedupeKey,然后创建新任务。
第二层:批量对账。 watchdog 每 60 秒扫一遍 DB 里所有 active 状态的任务,逐个去 BullMQ 查 Job 状态。terminal 或 missing 的任务被标记失败。
第三层:竞态保护。 不是发现脱节就立刻杀。terminal 状态给 90 秒宽限期(worker 可能刚执行完还没更新 DB),missing 状态给 30 秒宽限期(可能刚 createTask 还没 enqueue)。
为什么这值得抄?
因为没有这层对账的系统,在生产中一定会出现"僵尸任务"。用户点重试没反应(dedupeKey 被旧任务占着),余额被冻结但任务不动(freezeBalance 成功了但 Job 丢了)。这两个场景在高并发 + Redis 重启时必现。
CTO 判断:如果你自己造任务系统,这是必须实现的基础设施。没有它,你的客服团队每周要手动处理卡死任务。
三、Capability 组合定价——不靠"模型名 = 价格"
大多数系统的定价逻辑是 if model == 'kling' then price = 5。waoowaoo 的定价逻辑是:
模型 + 分辨率 + 时长 + 生成模式 + 是否带音频 → 查定价目录 → 单价 × 数量 × 加价率
定价目录是 JSON 文件(standards/pricing/image-video.pricing.json,138KB,覆盖所有 provider 和模型组合),有两种定价模式:
- flat:固定价格(
{ mode: "flat", flatAmount: 0.5 }) - capability:按能力组合分层(
{ mode: "capability", tiers: [{ when: { resolution: "1080p", duration: 5 }, amount: 3.0 }] })
关键设计:如果能力组合在目录里找不到匹配项,系统抛错,不走默认价。 错误码是 BILLING_UNKNOWN_VIDEO_CAPABILITY_COMBINATION。
为什么这值得抄?
因为"按模型名定价"在多供应商场景下一定会漏算。同一个模型,720p 5 秒的调用成本和 1080p 10 秒带音频的成本差 10 倍。如果你按模型名统一定价,要么高规格任务亏钱,要么低规格任务贵到用户跑掉。
另外,"找不到匹配就报错"比"找不到就用默认价"安全得多。默认价是静默亏损的温床。报错至少让你知道定价目录有缺口。
跟行业对比:Runway 的 API 按"生成信用点"扣费,不区分分辨率和时长,本质上就是"模型名 = 价格"。这意味着 Runway 自己在内部消化高规格任务的成本差异,而 waoowaoo 把它外化成了可运营的参数。
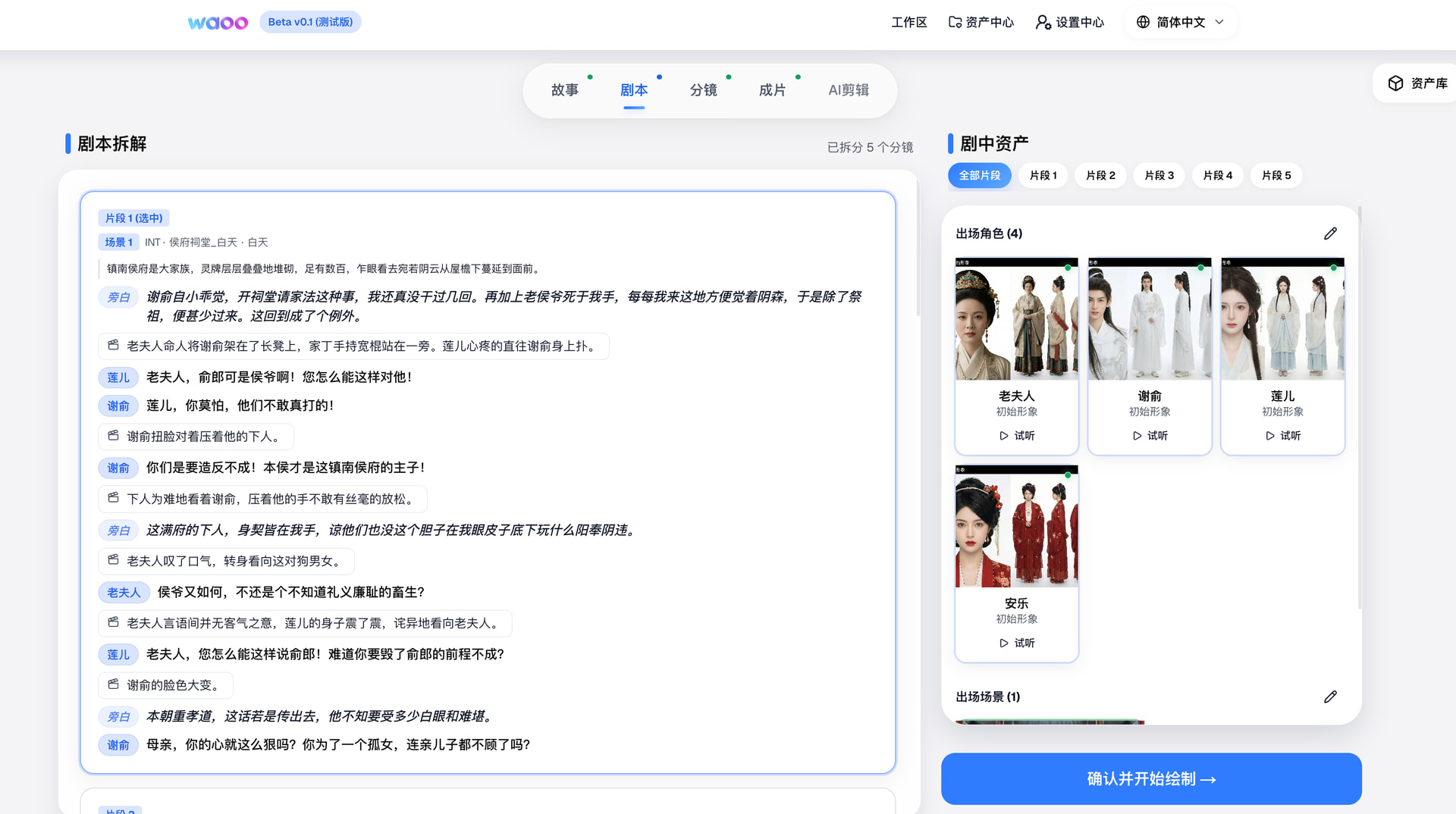
三样会炸
一、单进程 Watchdog——多实例部署必出重复对账
watchdog 是一个 setInterval,每 60 秒跑一次,跑在单独的 Node.js 进程里。
问题:如果你部署了 2 个实例(比如 Docker Compose 里 replicas: 2),就有 2 个 watchdog 同时扫描同一批任务。两个进程可能同时把同一个任务标记失败、同时触发 billing rollback。
虽然 rollbackFreeze 内部有 Prisma 事务保护(updateMany where status: 'pending' 只有一个能成功),不会真正双扣,但日志里会出现大量 BILLING_FREEZE_NOT_PENDING 错误,噪点极高。
怎么修:要么用 Redis 分布式锁保证只有一个 watchdog 实例在跑,要么用 BullMQ 的 Repeat 机制把巡检本身做成一个 Job。
CTO 判断:单实例部署没问题。但如果你要做高可用或水平扩展,这是第一个要改的地方。
二、冻结 ID 不是 UUID——高吞吐下可能碰撞
冻结记录的 ID 生成方式:
const freezeId = `freeze_${Date.now()}_${Math.random().toString(36).slice(2, 9)}`
Date.now() 是毫秒精度,Math.random().toString(36).slice(2, 9) 大约提供 36^7 ≈ 78 亿种可能。单机看起来够用。
但如果你跑多个 Worker 进程、每秒处理几百个任务,同一毫秒内两个进程生成相同随机后缀的概率不是零。碰撞后 Prisma 会抛唯一约束异常,冻结操作失败,用户看到的是"系统异常"。
怎么修:换 crypto.randomUUID(),或者用数据库序列生成。
CTO 判断:日活 1000 以下几乎不会遇到。日活过万、批量生成场景(一次提交几十个 panel)就需要改。
三、没有事件溯源——账本是可变状态,不是推导结果
余额是 UserBalance.balance 字段的一个数字,每次冻结/确认/回滚都直接 increment / decrement。流水记录(BalanceTransaction)是旁路写入的日志,不是余额的计算来源。
这意味着:如果某次事务部分失败(比如冻结成功了但流水没写进去),余额和流水就会不一致。你无法从流水重新推算出当前余额。
跟行业对比:金融级系统(如 Stripe、支付宝)的账本是事件溯源的——余额不是存储的,而是从所有交易事件推导出来的。这样即使某条记录出问题,可以从头重放。waoowaoo 的方式更像是"记账辅助的状态修改",不是真正的复式记账。
怎么修:长期来看,把余额改成从 BalanceTransaction 表计算得出(SELECT SUM(amount) FROM balance_transactions WHERE userId = ?),用缓存加速,但保证"交易记录 = 唯一真相源"。
CTO 判断:当前阶段可以接受。日活过万、用户开始较真"我的钱去哪了"的时候,这个架构债会变成信任危机。
拿来跟什么比?
维度
waoowaoo 自建
Runway/Pika API
自己从零搭
部署控制
完全自主
零控制
完全自主
计费粒度
panel 级别
信用点 / 按次
你自己定
供应商锁定
可切换 provider
锁死
你自己定
开箱即用
任务+计费+交付已成型
已成型但不可定制
从零写
规模化改造量
中等(本文列的三项)
不需要(也不允许)
全部自己写
什么时候选 waoowaoo:你要做自有品牌的短剧生产服务,需要控制成本和定价权,团队有 1-2 个全栈工程师能改源码。
什么时候选 Runway API:你只是在自己的产品里嵌入视频生成能力,不需要控制底层。
什么时候自建:你的业务逻辑跟"短剧生产"差异太大,waoowaoo 的领域模型(Project → Episode → Storyboard → Panel)套不上。
给 CTO 的总结
waoowaoo 不是一个"拿来就能赚钱"的系统,但它是一个"帮你省掉 60% 基础设施开发"的起点。
值得直接用的:SHADOW 计费模式、任务对账机制、capability 组合定价。这三样自建至少各需要一个工程师一个月。
上线前必须改的:watchdog 加分布式锁、冻结 ID 换 UUID、docker-compose 默认密钥全部替换。
中期要还的债:账本迁移到事件溯源、支付网关自动回调闭环。
先把 30 个 check 脚本跑通(npm run test:regression),确认你的改动没破坏现有约束,再往生产推。这套项目的 CI 约束脚本比大多数同体量的开源项目都严格,别绕过它。