软件工程里有一个老规律:每当一种新形态的应用大规模出现,先解决"看得见"问题的基础设施就会成为事实标准。Web 时代是 New Relic 和 Datadog,移动时代是 Crashlytics,云原生时代是 Prometheus 和 OpenTelemetry。LLM 应用这一波,正在出现自己的"看得见"层。
我个人比较看好的,是 Langfuse。
这不是因为它功能最多,也不是因为它跑得最快,而是因为它选了几个看起来朴素、但事后才会发现关键的工程取舍。这篇文章想把这些取舍拆开讲清楚,顺便回答一个我被问得最多的问题:单次调 LLM 也就那样,为什么我团队需要这么一套东西。
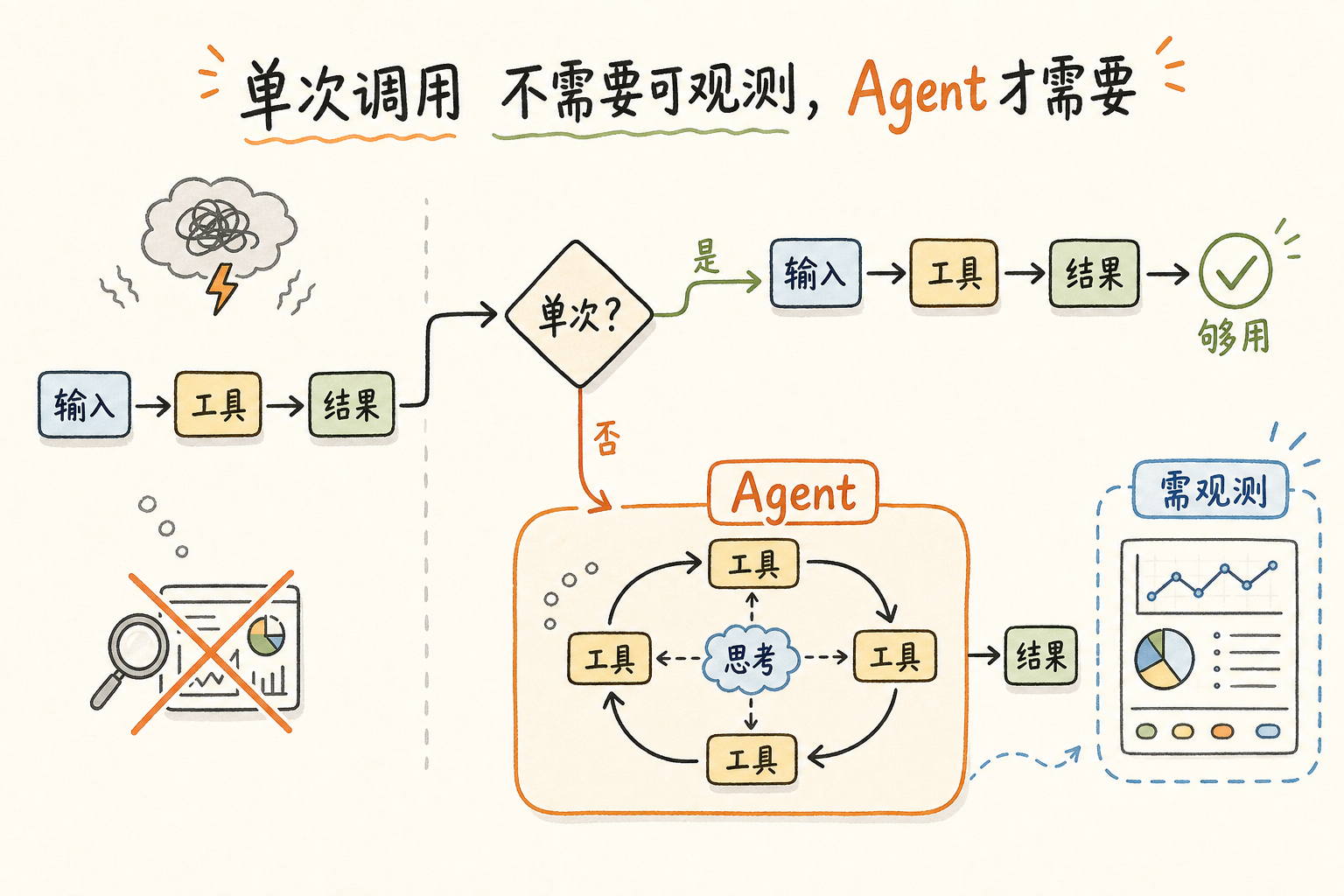
单次调用不需要可观测,Agent 才需要
去年我跟一个朋友聊,他做了一个内部聊天工具,包了一层 GPT-4,给运营同事问问题。功能很简单:用户输入,prompt 拼一下,调 OpenAI,结果回写界面。他说:"我加什么 Langfuse 啊,我就一行接口调用,OpenAI 的 dashboard 自己就有 token 统计。"
他说得对。
单次 LLM 调用是不需要可观测的。一个请求进、一个请求出,链路只有一跳。你要查谁烧了钱,OpenAI 后台够用;你要看 prompt 对不对,code 里面就是;你要测试效果,跑几个 case 肉眼看。整个心智模型跟"调一个 REST 接口"没区别。这种应用今天还很多,且确实不需要 LLMOps。
但今年我跟另外几个朋友聊,他们做的就不是这种东西了。他们做的是 Agent。
Agent 是另一个物种。一次用户请求进来,背后跑的不是一次 LLM 调用,是一棵树。第一次调用是 Planner,把任务拆成 5 步;第二次调用是工具选择,决定要不要查数据库;第三次调用是检索 reranker;第四次到第八次是循环执行;最后还有一次 Reflector 做自我反思。这棵树里,任何一个节点参数错了、上下文丢了、工具返回值格式不对,结果就是答非所问。而且日志里你只看得到最后那个荒诞的输出。
中间的 7 次 LLM 调用、3 次工具调用、4 次向量检索,全在内存里飘过去了。
这就是 LLMOps 真正开始有需求的地方。Agent 让 LLM 应用从一次性请求变成了多步状态机,从"调一个 API"变成了"跑一个分布式系统"。分布式系统不能没有可观测——这是过去三十年软件工程学到的最便宜也最深刻的一课。
所以判断你需不需要 LLMOps,不是看你用没用大模型,是看你的请求路径有几跳。一跳,OpenAI dashboard 够用。三跳以上,你迟早会买单。
Langfuse 是什么
Langfuse 是一个开源的 LLM 工程化平台。这句话每个词都重要:开源、LLM 专用、工程化(不是单纯监控)、平台(不是单点工具)。
它的 GitHub 仓库目前有 27.7k stars、2.8k forks、累计 563 个 release。在 LLMOps 这个细分赛道里,这是当前最大的开源项目。协议是 MIT,例外是 /ee 目录(企业版功能)。技术栈用 TypeScript 实现,存储层依赖 ClickHouse 做核心数据,Postgres 做事务数据。
它的四个核心模块覆盖了 LLM 应用全生命周期:
- Tracing:捕获你的应用每一步执行
- Prompt Management:把 prompt 从代码里抽出来集中管理
- Evaluations:自动给 LLM 输出打分
- Datasets 和 Playground:把生产数据沉淀成测试集
部署形态分两种。一种是 cloud.langfuse.com 的托管云,另一种是自部署,提供 Docker Compose、Kubernetes Helm chart、以及 AWS/Azure/GCP 的 Terraform 模板。两者用的是完全同一份代码库——这点对于愿意自己运维的团队是很大的承诺,意味着 Cloud 上验证过的能力在自部署版上不会缺失。
集成方式列表也值得提一下。这件事很多人不在意,但它直接决定了你接入的成本:
- OpenAI SDK:一行 import 替换(
from langfuse.openai import openai) - LangChain / LlamaIndex:callback handler
- Haystack:content tracing
- LiteLLM:proxy 层接,自动覆盖 100+ 模型
- Vercel AI SDK:原生支持
- 自己写的代码:用
@observe()装饰器手动埋点
对一个团队来说,能不能"今天下班前接好"取决于这个清单。Langfuse 的清单已经覆盖了 95% 的真实场景。
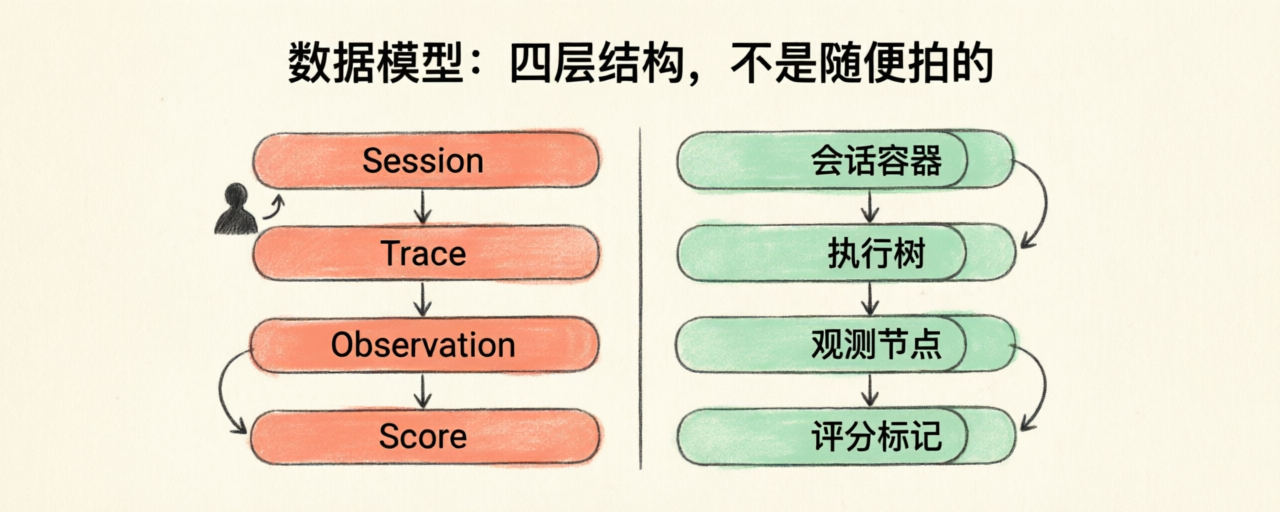
数据模型:四层结构,不是随便拍的
要理解一个可观测系统的设计取舍,先看它的数据模型。Langfuse 的模型是 Session → Trace → Observation → Score 四层。
Session 是最上层的可选容器,把多个 Trace 聚合成一次对话或一次会话。一个用户的多轮聊天,Session ID 一致,方便回放。
Trace 是一次完整的请求或操作。用户发一条消息进来,背后跑完整棵执行树,这棵树就是一个 Trace。Trace 上挂了一组属性:user_id、session_id、environment、tags、metadata、release、version。这些属性会自动下传给这个 Trace 下的所有 Observation——一个细节,但很重要。意味着你在 Trace 级打一个 tag,就不用在每一步重复打。
Observation 是 Trace 下的单步执行单元,可以嵌套。Observation 有三种类型:
Generation—— 一次 LLM 调用。带 model、input、output、token usage、costSpan—— 通用的执行步骤。比如一次 RAG 检索、一个工具调用Event—— 瞬时事件。比如某个 flag 被触发
为什么要分三种类型?因为它们的字段需求不一样。Generation 必须有 model 和 token 用量,Span 必须能嵌套,Event 是瞬时的不需要持续时长。把它们硬塞进一个模型里要么字段冗余,要么语义模糊。这个三分法看起来朴素,但实际上是踩过坑才得出的:早期一些观测工具就用一个统一的 span 概念,结果用户得自己约定哪个字段放 model、哪个字段放 cost,最后每家公司接入方式都不一样,分析也做不下去。
Score 是挂在 Trace 或 Observation 上的评分。这是 Langfuse 区别于纯日志型工具的地方——它从设计第一天就把"质量评分"作为一等公民。Score 的字段:
dataType:四种之一,NUMERIC、CATEGORICAL、BOOLEAN、TEXTvalue/stringValue:分值和字符串表示traceId/observationId/sessionId:关联 IDname:分数名称(例如hallucination、helpfulness)source:三种之一,API、HUMAN、MODEL_BASED_EVALid:幂等性键,用于更新
注意 source 这个字段。它把"人工标注的分""自动评估的分""SDK 上报的分"分开了。这意味着你可以在 UI 上对比"人工觉得好"和"GPT-4 评估觉得好"的差异——这是评估校准的基础工作。很多评估工具没设计这个字段,最后所有分都混在一起,无法判断信度。
整个数据模型加起来不到二十个字段,但每个字段都有具体的工程目的。这是 Langfuse 这套体系跑得动的根基。
Tracing 原理:异步、批量、不阻塞
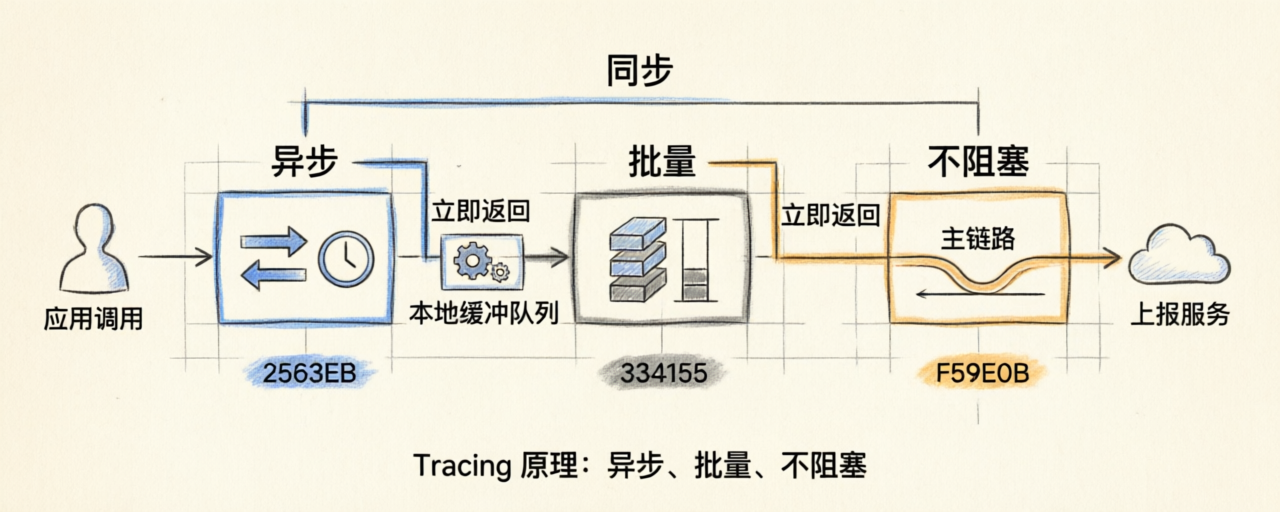
Tracing 这件事在 LLM 场景下有一个特殊的工程难点:LLM 调用本身就慢,平均一两秒,长的十几秒。如果可观测系统的上报再走同步、再加几百毫秒,用户体感就崩了。所以 Langfuse 的 SDK 设计原则只有一句话:永远不阻塞主链路。
具体怎么做的:
- SDK 在内部维护一个本地缓冲队列
- 应用调
langfuse.trace()或@observe(),只往队列里塞数据,立即返回 - 后台一个独立线程做批量 flush,按时间或大小触发
- flush 失败有重试,超过阈值丢弃但不影响主流程
- 短生命周期的应用(比如 Lambda),需要在退出前显式调
flush(),不然队列里的数据会丢
这是常见的可观测 SDK 设计模式,但放在 LLM 场景特别关键。因为 LLM 应用的请求时长本就长,如果可观测层再多一层延迟,可能直接被用户当成"应用慢"。Langfuse 把这一点做成了硬约束。
另一个值得说的是 SDK 集成方式。装饰器模式(@observe())是这套体系的灵魂。看下面这段代码:
from langfuse import observe
@observe()
def planner(task):
return llm.chat([...])
@observe()
def execute(step):
return tools.run(step)
@observe()
def agent(user_input):
plan = planner(user_input)
for step in plan:
execute(step)
完全没有显式的 trace API 调用,但 Langfuse SDK 会自动把这三个函数的调用关系串成一棵 Observation 树。这种"代码长得像没接入"的体感,是 SDK 设计的高级目标。OpenTelemetry 也是这个思路。
对一个写 Agent 的人来说,几乎不需要为可观测改代码——这是 Langfuse 能在 Agent 生态里跑起来的关键。
Prompt Management:把 Prompt 从代码里搬出去
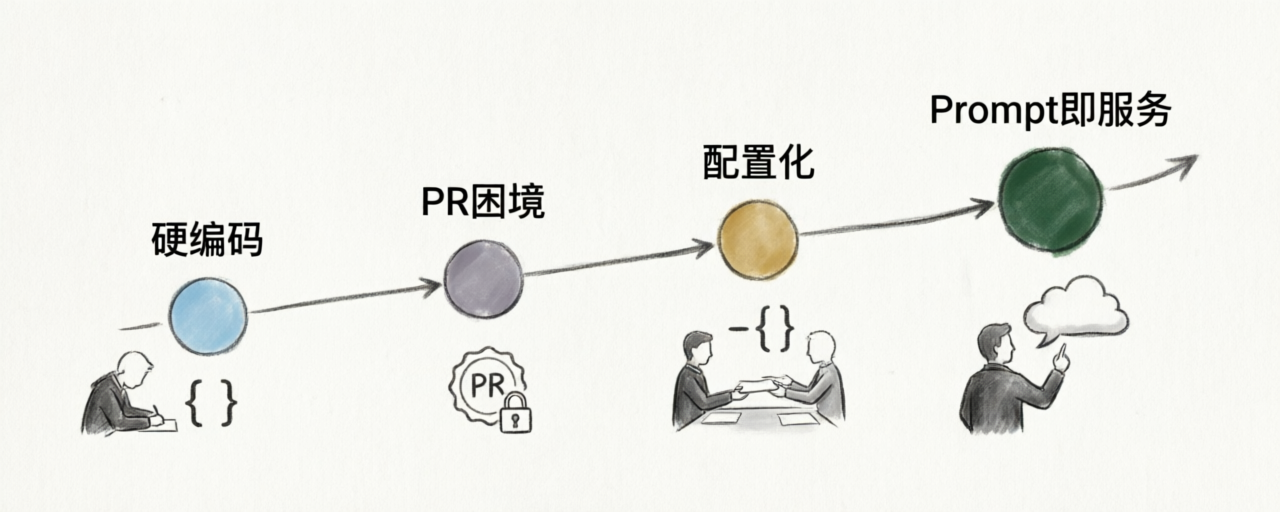
Prompt 管理这件事,几乎所有团队都经历过同样的曲线:
- 第一阶段:prompt 写在 Python 字符串里,跟代码一起提交
- 第二阶段:发现产品/运营经常要改 prompt,让他们提 PR 不现实
- 第三阶段:把 prompt 挪到 YAML 或 JSON 里,至少不用改 Python
- 第四阶段:YAML 也开始改不动了,要版本、要灰度、要 A/B、要回滚
到第四阶段,团队就需要 Prompt Management 这种东西。
Langfuse 的 Prompt Management 做了几件事:
版本化。同名 prompt 创建第二次,自动递增 v2。所有版本永久保留,可回滚。
Label 系统。每个版本可以挂一个或多个 label,比如 production、staging、exp-1。SDK 默认拉取 production 标签的版本。要灰度,就先把新版本挂 staging 验证,验证通过把 label 移到 production。要回滚,把 production label 移回旧版本即可。整个过程不需要发版。
两种类型:text(纯文本模板)和 chat(消息数组)。变量用 {{variable}} 注入。
客户端缓存。langfuse.get_prompt("name") 会做本地缓存,避免每次调用都打网络。缓存策略可配,默认情况下你改了 prompt 几秒钟内 SDK 会感知到。
与代码解耦。Prompt 改了不需要部署,应用启动时拉取或运行时拉取。一些团队甚至把 prompt 编辑权限交给产品同事,工程师只管接口。
这套体系真正解决的不是技术问题,是组织问题。Prompt 是一种特殊的"代码"——它的迭代频率比代码高一个量级,决策者经常不是工程师,而是产品、运营、领域专家。把它和代码分开管,是工程化的必经之路。
Evaluations:让 GPT-4 当裁判
LLM 应用最难的不是写出来,是知道写得好不好。
传统软件有单元测试、集成测试、回归测试,标准答案明确,pass 或 fail。LLM 应用的"对"是一个模糊的范围。模型输出"答案大致对、语气稍有偏差",单元测试根本测不出来。靠人工肉眼测,一个版本几百个 case,迭代速度立刻被卡死。
LLM-as-a-judge(让大模型当裁判)就是这一两年逐渐被接受的方案。思路是用一个能力更强的 LLM 评估一个待测 LLM 的输出,结合人类标注做校准。Langfuse 的 Evaluations 模块就是这套思路的工程化。
它的内置评估器包括:
Hallucination—— 幻觉检测:输出是不是凭空编造Helpfulness—— 有用性:是否真正回答了问题Context-Relevance—— 上下文相关性:RAG 召回是否相关Toxicity—— 毒性:内容是否合规- 以及其他若干维度
配置流程是这样的:
- 选择评估目标。生产环境用 Observation-level evaluator,秒级出结果;开发环境用 Experiments(在 dataset 上做对照实验)。
- 选评判模型。要求是支持结构化输出的,比如 GPT-4o、Claude Sonnet。
- 写评估 prompt,使用
{{input}}、{{output}}、{{ground_truth}}这些变量占位符。 - 选评分类型,Numeric / Categorical / Boolean。
变量映射这一步支持 JSONPath,能精确定位嵌套字段。UI 提供实时预览,用过去 24 小时的真实数据验证映射对不对——这个细节很重要,否则你写完 evaluator 不知道字段拼对了没有,要等几小时才看到数据,调试成本巨大。
成本控制是 Evaluations 真正用得起来的关键。每次评估调一次 GPT-4o,根据输入长度,单次成本 $0.01-0.10。如果你的生产环境每天 100 万次 trace,每次都评估,月度成本就是 30 万到 300 万美元——任何 CFO 都不会签。
所以官方推荐三种成本优化方式:
- 采样:只评估 5%-10% 的流量
- 定向:只对特定 tag 或特定 prompt 的 trace 评估
- 用便宜模型:评估器用 Claude Haiku 或 GPT-4o-mini,复杂场景才升 GPT-4o
我个人比较推荐的策略是:production 流量采样 5% 评估,每日定时跑一遍最近 24 小时的 dataset 完整评估,做趋势监控。这样既不亏钱又能抓质量回归。
Datasets:把生产数据沉淀为测试集
LLM 应用最值钱的资产是什么?不是代码,是真实数据。真实用户怎么提问、真实场景下模型怎么翻车、真实 RAG 召回错在哪里——这些数据用钱都买不到,只有跑在生产里才能积累。
Langfuse 的 Datasets 模块就是把这件事工程化。它做的事情很简单:
- 在 trace 列表里看到一个有价值的 case(比如失败的、有趣的、边界情况的),点一下"加入 dataset"
- Dataset 是一组
(input, expected_output, metadata)三元组 - 在 Experiments 里选一个 dataset,挂上你的 Agent 实现,跑一遍
- 自动用 evaluator 给每条结果打分
- 看实验结果与上一次实验的差异
听起来朴素,但实际用起来威力不小。你的迭代节奏从"改完上线让用户测"变成"改完跑 dataset 看分数",反馈周期从天级缩短到分钟级。
更关键的是它解决了"质量回归"问题。每次发版前,把现有的 dataset 跑一遍,对比上一版本的分数分布。如果新版本在某些维度跌了,立刻知道。这是传统软件里 CI 跑测试的等价物,只不过这里跑的是 LLM 评估。
一个比较成熟的工作流是这样:
- 生产环境跑着,所有 trace 进 Langfuse
- 工程师每周花 30 分钟看失败 case,把典型的加入 dataset
- 每次改 prompt 或换模型,跑 dataset 看结果
- 把通过的合并,把失败的回滚
- Dataset 越来越大,覆盖越来越全
半年下来这个 dataset 就是你团队最值钱的资产之一。它沉淀了所有踩过的坑、所有 corner case、所有用户的真实诉求。新人来了,跑一遍 dataset 就能感受到这个产品的边界。
Datasets 这种"生产 → 测试集 → 实验 → 回写生产"的闭环,是 LLM 应用工程化的核心循环。Langfuse 把这个循环做完整了,这是它和很多只做 tracing 的工具的分水岭。
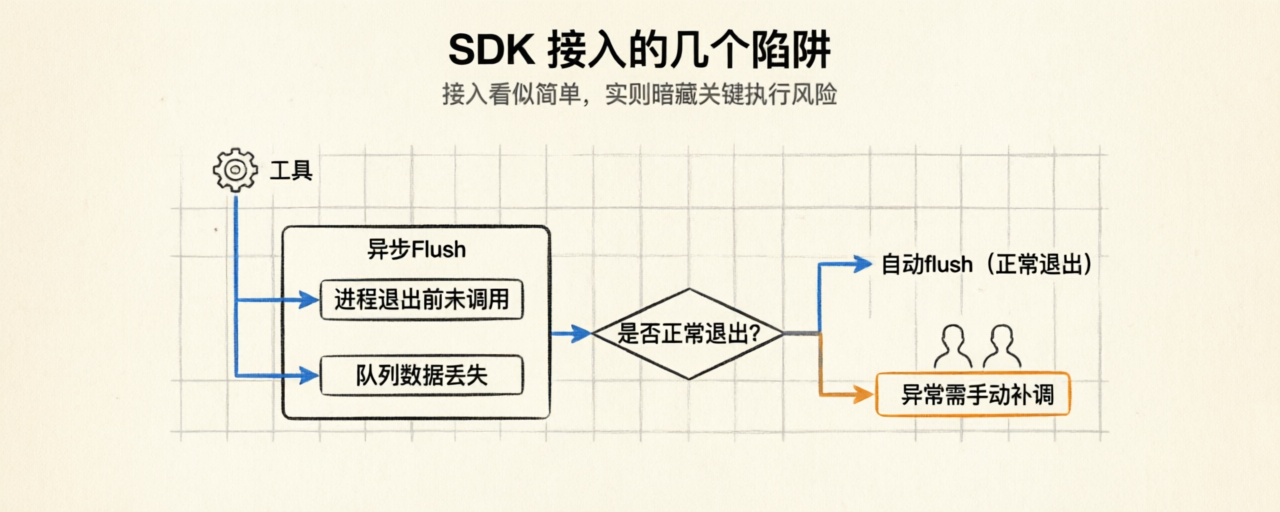
SDK 接入的几个陷阱
接入这件事看着简单,但有几个陷阱踩到了会很难受。这里梳理几个。
陷阱一:异步 flush 没调用,数据丢了
短生命周期应用(Lambda、Cloud Functions、CLI 工具)容易踩。SDK 是异步 flush 的,进程退出前如果没主动调 langfuse.flush(),队列里的数据会丢失。
import atexit
from langfuse import Langfuse
langfuse = Langfuse()
atexit.register(langfuse.flush)
加这一行,所有正常退出都会 flush。异常退出还是会丢,需要在异常处理里也加一次。
陷阱二:装饰器的 trace 边界
@observe() 装饰器默认每次函数调用产生一个 Observation。如果你的 Agent 入口函数被装饰,每次用户请求是一个 Trace。如果你只装饰内部的 LLM 调用函数,每次调用就只是一个 Observation,没有顶层 Trace。
@observe() # 这是 Trace 起点
def agent_entry(user_input):
return planner(user_input)
@observe() # 这是 Observation
def planner(input):
return llm_call(input)
新人常犯的错是只装饰最内层,结果在 UI 看到一堆孤立的 Generation,没有 Trace 把它们串起来。
陷阱三:sensitive data 没脱敏
LLM 输入输出经常包含用户 PII(手机号、邮箱、身份证)。直接上报到 Langfuse,trace 数据里就有了。Cloud 版还涉及合规——这就是为什么国内团队倾向自部署。
Langfuse 提供 mask 函数 hook,可以在上报前做脱敏:
def mask_pii(data):
# 你的脱敏逻辑
return cleaned_data
langfuse = Langfuse(mask=mask_pii)
接入第一天就要想清楚脱敏策略,不要等数据已经上报了再补救。
陷阱四:trace 太多查不动
ClickHouse 的强项是聚合分析,不是大量明细查询。如果你 trace 量极大(每天百万级以上),UI 上拉明细列表会慢。解决办法是合理打 tag,把常用筛选条件物化成 tag——environment、tenant_id、feature_flag 这些。Langfuse UI 的过滤几乎都建在这些 tag 上。
陷阱五:自部署忘了 S3
很多人自部署只配了 ClickHouse 和 Postgres,没配 S3 兼容的对象存储(用 MinIO 也行)。结果原始事件写不进去,整个 ingestion 链路 broken。S3 不是可选项,是必需项。
这些陷阱大部分文档里都有说,但分散在不同页面。接入前花一小时把这些点过一遍,比上线后救火便宜得多。
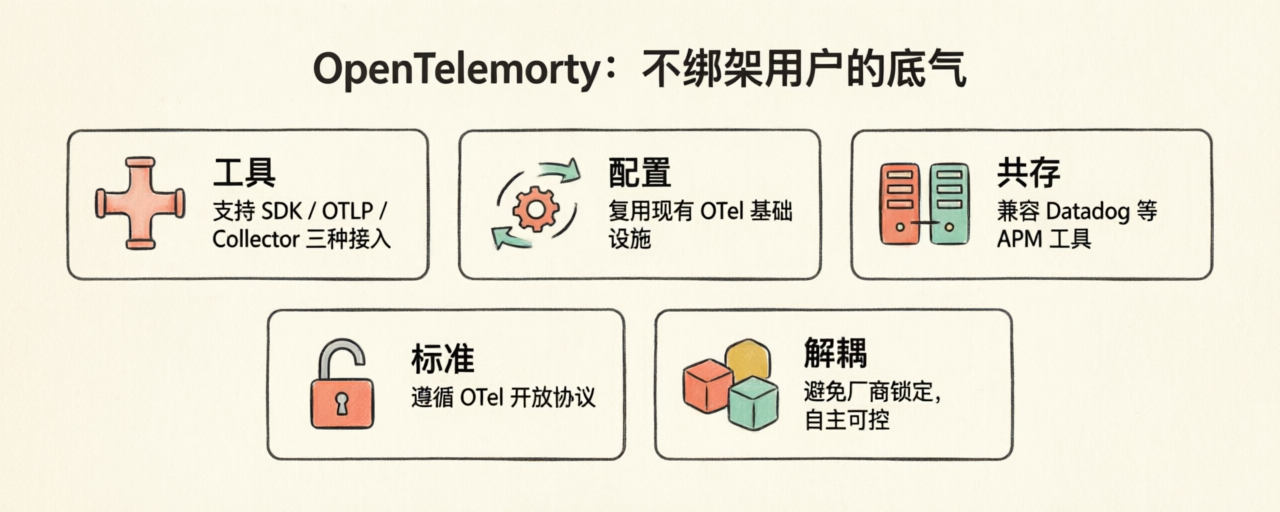
OpenTelemetry:不绑架用户的底气
Langfuse 的 tracing 数据格式是基于 OpenTelemetry 标准的。这件事在 LLMOps 工具里不是默认操作——很多家都搞了自己的协议。
Langfuse 选 OTel 有三个具体好处:
第一,接入路径多元。它原生支持三种方式:用 Langfuse SDK v4(内建 OTel)、用任何 OTLP-compatible 客户端打 /api/public/otel endpoint、或者通过 OTel Collector 转发。这意味着如果你团队已经有 OTel 基础设施,可以直接复用。
第二,和现有 APM 共存。你的应用同时打数据给 Datadog 和 Langfuse,技术上没有冲突(虽然官方文档提到多 exporter 配置时要注意 SDK 实例隔离)。Langfuse 抓 LLM 维度,Datadog 抓 infra 维度,互不打扰。
第三,遵循 GenAI 语义约定。OpenTelemetry 社区在推 gen_ai.* 命名空间作为 LLM 应用的标准 attribute 集合:gen_ai.system、gen_ai.request.model、gen_ai.usage.prompt_tokens 这些。Langfuse 完全兼容这套约定,并补充了自己的 langfuse.* 命名空间用于内部数据。属性优先级是 langfuse.* > gen_ai.*。
实际配置很轻:
OTEL_EXPORTER_OTLP_ENDPOINT="https://cloud.langfuse.com/api/public/otel"
OTEL_EXPORTER_OTLP_HEADERS="Authorization=Basic [BASE64编码的API密钥]"
支持 EU / US / Japan / HIPAA 四个数据区域,合规需求基本覆盖。
这个选择的深层意义是:Langfuse 不试图绑架用户。今天你用它,明天你想换 LangSmith 或者自己搭一套,数据格式都是 OTel 标准,迁移成本是有限的。这个心态在 SaaS 时代越来越稀缺。
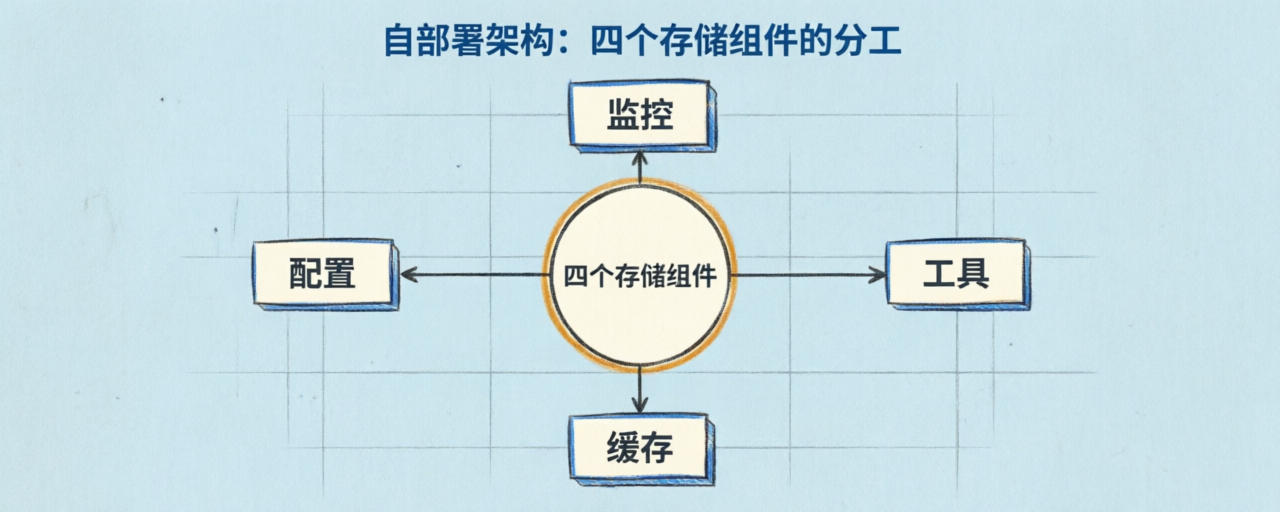
自部署架构:四个存储组件的分工
很多人第一次看 Langfuse 的部署文档会惊讶——一个 LLM 监控工具,怎么需要四个存储组件?这套架构看着重,但每一个组件都有具体不可替代的作用。
PostgreSQL:OLTP 层。存配置(项目、用户、API key、prompt 定义、评估器配置)这种强一致性、低写入量、需要事务的数据。行存数据库的传统场景。
ClickHouse:OLAP 层。存核心的 traces、observations、scores 数据。列存的核心优势是高压缩率(10x 以上)和聚合查询性能。LLM trace 是典型的高写入、按维度聚合分析的负载——按用户分组、按 tag 分组、按时间窗口 rollup——这正是 ClickHouse 的强项。
Redis / Valkey:内存层。做两件事——队列管理(异步 ingestion)和热点缓存(API key、热门 prompt)。
S3 / Blob Storage:对象存储层。存原始事件、多模态输入(图片、视频)、大型导出。廉价、几乎无限容量。
四个组件协同工作的核心数据流是这样的:
Client SDK
↓ 批量异步上报
Web 服务器
↓ 立即写 S3,留引用在 Redis 队列
S3(持久化原始事件)
↓ Worker 异步消费
ClickHouse(最终可查询库)
Web 服务器的职责是"快速接收 + 持久化原始数据",完全不做加工。所有的加工——结构化、聚合、写入分析库——都在异步 Worker 里完成。这种"写路径和查询路径解耦"的设计能扛巨大的流量尖峰。Agent 应用的请求流量是非常突发性的,一个客户搞活动可能瞬间几十倍流量,这种架构就显出价值。
Worker 还顺带跑模型评估(model-based evals)。资源复用,运维简洁。
部署规模分两档:
- 小规模(测试、demo、个人项目):Docker Compose 单机,无 HA,但能跑完整功能
- 生产规模:Kubernetes(Helm chart)或云厂商 Terraform 模板,支持自动扩展、备份、故障转移
自部署版和 Cloud 用的是同一份代码——这是我前面强调过的点,值得再说一次。
横向对比:LangSmith、Phoenix、Helicone
LLMOps 这个赛道现在大概有 4 家值得关注的工具。把它们放在一起看,能更清楚 Langfuse 的位置。
维度
Langfuse
LangSmith
Phoenix
Helicone
协议
MIT
闭源
Elastic License 2.0
Apache 2.0
公司背景
独立公司
LangChain 同公司
Arize AI
YC W23
部署
Cloud + 自部署
Cloud + 自部署 + 混合
Local + Cloud
Cloud + 自部署
技术路线
SDK 埋点 + OTel
SDK 埋点
OTel + OpenInference
AI Gateway + 异步 SDK
生态绑定
框架无关
与 LangChain 同公司
与 Arize 商业产品
独立
社区规模
27.7k stars
闭源不可见
9.8k stars
数据未公开
突出特点
全栈、社区大
企业认证齐
Notebook 友好
Gateway 路线
几个看起来反共识但我比较确定的判断:
LangSmith 不是 Langfuse 真正的竞争对手。原因有两个。一是协议不同,闭源工具在企业自部署场景永远过不去那个心理门槛。二是品牌定位绑定 LangChain,没用 LangChain 的团队天然有距离感,而今天大家越来越不用 LangChain 直接写 Agent(用更轻量的方案居多)。LangSmith 的市场是"已经深度使用 LangChain 的存量用户",不是新增市场。
Phoenix 才是 Langfuse 的真正同位竞争。它也开源、也走 OpenTelemetry、也做全栈 LLMOps。区别只在一些细节:
- Phoenix 用的是 Elastic License 2.0,理论上有商用限制风险(虽然实际使用几乎不会触发)
- Phoenix 的 Notebook / 本地开发体验更好,从 Jupyter 起家,研究场景顺手
- Langfuse 的生产部署体验更成熟,从工程化起家
- 社区规模 Langfuse 大三倍
如果你团队是研究院或者 ML 团队为主,Phoenix 可能更顺手。如果是工程团队接业务做 Agent,Langfuse 的工程化更稳。
Helicone 走的是另一条路,长期可能更激进。它的核心是 AI Gateway——通过 proxy 拦截所有 LLM 调用,顺带做观测。这条路线的附加值更厚:Gateway 不仅能观测,还能做模型路由、自动 fallback、缓存、计费分流。一个客户为什么需要 Gateway?因为他可能同时用 OpenAI、Anthropic、自部署 Llama,需要一个统一控制平面。一旦 Gateway 起来了,观测只是它附带的副产品。
Langfuse 是观测视角,Helicone 是控制平面视角。前者更适合"我已经写完代码,想看看跑得怎么样",后者更适合"我从一开始就想统一管理我的 LLM 流量"。
长期来看,Gateway 路线的天花板更高,但短期 Langfuse 的可观测能力更深、更专。这两家未必会冲突——可能最终演化成"用 Helicone 当 Gateway,把 trace 转发给 Langfuse"。这种组合我已经在一些团队里见到了。

三个真实场景
抽象讲了这么多,看三个具体场景。这是 Langfuse 这套体系真正发挥价值的地方。
场景一:多步 Agent 调试
某团队做了一个客服 Agent,能调订单系统、查物流、查会员等级。某天用户报告说:"我问'帮我取消订单 12345',它居然回了我的会员积分。"
没接观测前,团队的工程师能拿到的只有:
- 用户的 raw input
- Agent 的最终输出(关于会员积分的回答)
- 中间过程:黑盒
接了 Langfuse 之后,工程师打开 trace 树展开,发现:
- Planner 阶段,把"取消订单"分类成了
QUERY而不是ACTION(因为 prompt 里关键词列表没覆盖"取消"这个词的中文变体) - 走 QUERY 分支后,Router 选择了"会员相关查询",因为用户 message 里出现了"订单"——但订单查询和会员查询的 keyword overlap 让 Router 跑偏了
- 最终 LLM 拿到的 system prompt 是"你是一个会员积分查询助手",所以输出当然是积分
整个排查从原本要花半天看日志,变成 5 分钟看 trace。
更关键的是,这种 bug 不修代码层。它修 Planner 的 prompt——加几个 keyword。修完之后,工程师把这次失败的 trace 加进 dataset,跑一遍回归——确认修复有效且没影响其他用例。整个闭环 30 分钟内完成。
这就是为什么 Agent 时代必须有可观测。同样的 bug,没有可观测,就是猜半天看代码;有了,就是定位、修复、验证 30 分钟收工。
场景二:RAG 召回质量回归
某团队做了一个企业内部知识库问答系统。上线半年稳定运行,月初他们把 embedding 模型从 text-embedding-ada-002 换到了 text-embedding-3-large,理论上质量更好。换完一周,用户反馈"答非所问"的比例上升了。
肉眼抽查 case,工程师怀疑是新 embedding 模型在中英混合的查询上召回质量下降了——但说不准,没数据。
接了 Langfuse 之后,做法是这样的:
- 用 LLM-as-judge 的
Context-Relevance评估器,给所有 RAG 检索的 observation 打分 - 在 UI 里按
release维度分组——旧 embedding 模型时段 vs 新 embedding 模型时段 - 看分布
结果一目了然:新模型在英文查询上分数略升,在中文查询上分数明显下降,混合查询掉得最厉害。
定位到原因后修复也清楚了——给中文查询单独走旧模型,或者用一个 multilingual 强的 embedding 替代。
这种问题没 Langfuse 也能排查,但你得自己搭一套评估管道,自己写 dump、自己跑 GPT-4 评分、自己出报表。从零搭这套大概要一两周。Langfuse 把这一步变成几分钟的 UI 配置。
场景三:Token 成本归因
某团队某月 LLM 账单暴涨 3 倍,从月度 8000 美元飙到 24000 美元。流量没明显涨,工程师猜不出哪儿出了问题。
接 Langfuse 之后,第一件事是按 user_id 分组看 token 消耗。果然——某个企业客户的某几个用户,单月消耗占了总量的 40%。再展开 trace 看,发现这些用户在做"长文档摘要"功能,上传的文档动不动几十页,每次摘要要做 6-8 次 LLM 调用(分段处理),每次都把整段塞进 context。
归因清楚了,方案也清楚了:
- 长文档场景上预处理,先用 embedding 找出最相关的部分,只把这部分塞进 context
- 或者对这个客户启用单独的更便宜的模型
- 或者直接按用量分账,把成本传导出去
无论哪种方案,前提是你得先知道钱花在哪儿了。这件事 OpenAI 的 dashboard 给不了你——它只能按 API key 分账,分不到 user 维度。
成本归因是 LLMOps 工具最容易被低估、但 ROI 最直接的能力。一个企业从月度账单里省下 30%,省的钱可能是 Langfuse Cloud 订阅费的几十倍。
从其他工具迁移过来
如果你团队已经在用其他 LLMOps 工具,要不要换?这取决于你在用什么、迁移成本有多大。
从 LangSmith 迁移。技术上不难。LangSmith 的数据模型也是 trace/span/score,概念能对得上。Langfuse 的 LangChain integration 也成熟,callback handler 几乎一样的接入方式。但 LangSmith 的 prompt hub 和 datasets 数据要导出再导入,目前没有官方迁移工具,得自己写脚本。如果你的团队主要是看中开源和自部署,迁移是值得的;如果你已经买了 LangSmith 企业版且用得顺手,没动力换。
从 Phoenix 迁移。这是最顺滑的,因为两边都基于 OpenTelemetry。Phoenix 用的是 OpenInference 语义约定,Langfuse 兼容 OTel GenAI 约定,但 OpenInference 的字段大部分能直接映射。Phoenix 的 Notebook 体验 Langfuse 比不上,但 Langfuse 的生产部署更稳。这个迁移决策更多看团队偏好——研究团队留 Phoenix,工程团队换 Langfuse。
从 Helicone 迁移。这是最尴尬的,因为路线不一样。Helicone 是 Gateway,拦截你所有的 LLM 流量;Langfuse 是 SDK 埋点,跟着你的代码走。换的话相当于换架构——Gateway 撤掉,代码里加 SDK。如果你已经依赖 Helicone 的 fallback、缓存、路由功能,单纯换 Langfuse 是有功能缺失的,得自己实现这些。所以这两家更多是"一起用"而不是"换"——Helicone 当 Gateway,Langfuse 当观测。
从自建系统迁移。我见过一些团队自己写了简单的 trace 记录、自己存 Mongo、自己做 dashboard。一开始能用,但维护成本会指数上升——加一个评估维度要改三个地方,新增一个 SDK 集成要写大量胶水代码。这种自建系统的归宿基本都是被开源工具取代。Langfuse 的接入难度比维护自建系统低一个数量级,迁移 ROI 最高。
迁移这件事最大的成本不是技术,是组织习惯。一个团队用了半年的工具,UI 形成了肌肉记忆,工作流跟工具绑定。换工具意味着大家要重新学。所以建议:先并行跑两个月,让团队自然过渡,不要一刀切。
反共识观点:国内自部署才是核心场景
最后讲一个国内同行可能会有共鸣的判断。
很多人看 Langfuse,第一反应是去 cloud.langfuse.com 注册账号,把 SDK 接上,开始用。这是海外创业团队的标准动作。但我在国内看到的真实情况几乎反过来——绝大多数想用 Langfuse 的团队,第一步是研究怎么自部署。
原因有三个:
合规要求。LLM trace 里包含用户输入和 LLM 输出,这是高度敏感的内容数据。把这些数据传到一个海外 SaaS,且这家公司在美国——大部分国内 To B 客户的合规审计会直接卡掉。
网络可用性。cloud.langfuse.com 在国内的访问质量不稳定。SDK 异步上报失败率高,本来可观测系统应该 99.9% 可用,掉到 99% 就开始影响数据完整性。
成本。Cloud 按 trace 数量阶梯定价,对中等规模的 Agent 应用,月度费用很容易上千美元。同样的钱在国内用阿里云或者私有机房自部署,性能更好。
所以国内的真实用法是:起步阶段用 Cloud 跑通,验证产品价值之后立即迁移到自部署版本。Langfuse 的好运在于,自部署版和 Cloud 完全代码一致——这件事在闭源工具上是不可能做到的。
这也是为什么我前面强调 ClickHouse、Postgres、Redis、S3 这套技术栈很重要。这四个组件全部是国内团队熟悉的开源栈,运维成本远低于一个全新的存储栈。一个有 K8s 运维基础的团队,部署完整的 Langfuse 集群两天能跑起来。
国内 LLMOps 这个市场,最终竞争不是在 Cloud 体验上,而是在"自部署成熟度 + 国内技术栈兼容性"上。从这个角度看,Langfuse 的技术选型是踩在点上的——MIT 开源、OTel 标准、主流存储栈、文档完整。
一个工程团队的选择框架
如果你要在 Langfuse、Phoenix、Helicone、LangSmith 之间做选择,下面这套框架可能更直接。
第一问:你能不能接受闭源工具?
不能 → 排除 LangSmith。
能 → 继续。
第二问:你的核心需求是 Gateway 还是观测?
Gateway(多模型路由、统一计费、自动 fallback)→ Helicone。
纯观测和评估 → 继续。
第三问:你的团队主要场景是研究/Notebook 还是生产工程?
研究/Notebook 居多 → Phoenix。
生产工程居多 → Langfuse。
第四问:你需不需要自部署?
需要 → Langfuse 是综合体验最好的。Phoenix 也行但生产部署文档不如 Langfuse。
不需要(用 Cloud 就行)→ 三家都可以,看具体功能匹配度。
第五问:你团队对 OpenTelemetry 熟不熟?
熟 → 任何一家的 OTel 路径都行。
不熟 → Langfuse 的 drop-in SDK 更友好,几乎不用懂 OTel 概念。
走完这五问,你大概率能定下来。我自己接触过的大部分团队最后选了 Langfuse,但不是因为它"最好",是因为它的取舍跟大部分工程团队的需求最匹配——开源、自部署友好、不需要先理解 OTel、SDK 顺手、社区活跃出问题能搜到答案。
工具选择从来不是选"最强",是选"最匹配你团队当前状态"。Langfuse 不是没有缺点,比如 UI 在某些细节上不如 LangSmith 精致、Notebook 体验不如 Phoenix。但综合权衡下来,它的"短板比较短、长板比较长"。
一个更大的判断:LLMOps 还在早期
最后讲一个更长期的观察。
LLMOps 这个赛道,今天看起来已经有 4 家成熟工具了,但它远没有到稳定状态。整个领域大概等价于 2008 年的 APM 市场——已经有 New Relic 这种领头羊,但具体的产品形态、最佳实践、商业模式都还在演化。
接下来 12 到 24 个月,可能会发生几件事:
Agent 框架和 LLMOps 工具会更深度绑定。今天 LangChain、LlamaIndex、CrewAI 这些框架都有自己偏好的观测方案。但 Agent 框架本身还在快速变化,谁会胜出不确定。LLMOps 工具要么押注某一家,要么保持框架无关。Langfuse 选了后者,长期看是正确的选择。
评估能力会变成核心差异化。今天大家比的是 tracing 谁更顺手,未来会比谁的评估能力更强、更便宜、更准确。Langfuse 在这方面已经下了功夫,但还有提升空间——比如多模态评估、Agent 级评估(不止是单步评估)、对话级评估。
自部署会变成主流。今天 Cloud 是默认推荐,但企业客户进入后会逐渐转向自部署。Langfuse 已经在这条路上走得最远。
Gateway 和观测会融合。Helicone 已经在尝试做"Gateway + 观测",Langfuse 可能也会反向加 Gateway 能力,或者通过和 Helicone 这类工具合作。未来的 LLMOps 平台可能是"统一控制平面 + 全栈观测"的形态。
评估会标准化。今天每家都有自己的评估器和打分体系。未来可能出现 LLM 评估的标准格式,类似 OpenTelemetry 之于追踪。这会让评估器跨平台复用,整个生态成熟得更快。
这些是我的判断,不一定对。但有一点比较确定:现在投入到 LLMOps 工程实践里,是性价比很高的投资。两年后这套体系会变成 LLM 应用的标配,谁早一年积累,谁就早一年享受到工程化红利。
短期能用、长期看好
回到开头那个问题:你需不需要这套东西?
短期内的判断标准很简单。看三件事:
- 你的应用是单次 LLM 调用还是多步 Agent?后者必须有
- 你的 prompt 是写在代码里的还是经常要改?经常改的需要管理
- 你的 LLM 账单看不看得懂?看不懂的需要归因
满足任意一条,Langfuse 这套体系就是值得花一两天接入的投资。
长期我的判断是这样的:LLMOps 会像 APM 一样成为标配。十五年前没人觉得 APM 是必需品,"加个监控嘛,写两行日志够了"。今天没人这么想。LLM 应用走的是同一条路——一开始觉得不需要,等多步 Agent 在线上跑了一阵,开始有奇怪的 bug、有跑飞的成本、有用户投诉,团队会自己长出可观测的需求。
到那时候,选哪一家会变成一个具体问题。我个人比较看好 Langfuse,理由这篇文章已经讲完了。Phoenix 也值得关注,特别是研究场景。Helicone 的 Gateway 路线长期想象空间最大,值得保持关注。LangSmith 适合已经深度用 LangChain 的存量团队。
工具选错不是大事,能换。但如果你的 Agent 已经在线上跑了三个月还没接可观测——那个才是真的问题。
参考资料: