
2026-02-03,OpenAI 上线了 Codex(带 GUI 的 Codex app)。我最在意的不是“它又把补全做得多聪明”,而是它把工程团队里那些没人愿意做、但又必须做的活,正式提到台前:Automations。
想象一个很具体的场景:
你早上打开电脑,发现昨晚有人 merge 了一个看似无害的小 PR;CI 还没红,但线上监控已经开始抖;你在 Slack 里被 @ 了三次;而你真正想做的是推进一个关键 feature。
Automations 的意义在于:把“维护工程系统的日常杂活”变成可持续的后台生产线,让人回到“做决定”和“做创造”的位置。
参考:OpenAI Codex 产品页(英文)与繁中页(只引用页面原文信息,不做扩写)
- https://openai.com/codex/
- https://openai.com/zh-Hant-HK/codex/
先把术语说清楚:Codex app / Skills / Automations 到底分别是什么
1) Codex app:不是一个模型,而是一个“指挥中心”
OpenAI 在页面里把 Codex app 描述为 “command center for agentic coding”:
- 有内置 worktrees
- 有云端环境
- 允许多个 agent 并行在不同项目/分支上工作
这句话的潜台词是:它想把“写代码”从一个人盯着 IDE 的流程,变成类似“调度任务”的流程。
2) Skills:把团队标准变成可复用能力
产品页里提到:通过 Skills,Codex 不止写代码,还能做“理解代码、制作原型、写文档”,并且对齐团队标准。
我理解这里的关键不是“多了一个插件系统”,而是:
- 把团队里那些隐性规范(目录结构、测试哲学、review 习惯)显性化
- 让 agent 的产出更像“团队成员”而不是“随机外包”
3) Automations:真正的变化——让 agent 在后台“无提示”工作
产品页对 Automations 的描述非常直接:
“With Automations, Codex works unprompted, picking up routine but important work like issue triage, alert monitoring, CI/CD…”
这里最容易被误解的一点是:
- Automations 不是“定时跑个脚本”那么简单
- 它更像把工程活动拆成一组可触发、可校验、可回滚的后台任务
为什么现在大家都在推 Automations:三股力量把它推到门口
1) 代码规模上来了,但“工程债务”一直没降
当 repo 变大、依赖变多、CI 更复杂,维护成本不是线性增长,是指数式地挤占“做新东西”的时间。
2) 真实的工程效率瓶颈不在“写”,而在“协作与验证”
很多团队并不缺能写的人,缺的是:
- 能把改动解释清楚的人(release notes / changelog)
- 能把问题归因清楚的人(CI flake / incident)
- 能把风险提早暴露的人(regression / dependency drift)
3) 多 agent 并行让“碎任务”第一次变得划算
如果你只有一个 agent,做完一个 task 还要你继续 prompt。
但当你有一个调度层,可以并行开工:
- A 追踪 CI
- B 扫描 commits
- C 生成 release notes
- D 跟进 issue triage
“碎任务”就可以像流水线一样被吞掉。
我对 Automations 的批判:它会让团队更强,也更危险
问题 1:可验证性(Verifiability)是硬门槛
Automations 做的很多事(比如“发现潜在 Bug”)天然带推断。
如果没有明确的校验机制,它会变成:
- 写得很像对的建议
- 但无法被快速证伪
我的底线是:
- 自动化可以提出假设
- 但必须附带“如何验证/如何回滚/影响范围”
问题 2:激励结构会被改变:人可能开始“依赖机器的解释”
一旦 release notes、weekly update 都自动生成,团队容易把“解释工作”外包给机器。
长远看会发生两件事:
- 解释能力退化(尤其是 junior)
- 语义漂移(自动总结逐步偏离真实决策记录)
因此 Automations 需要一个很现实的定位:
- 它是“草稿生成器”和“报警器”
- 不是“最终事实的记录者”
把你给的 Automations 清单,翻译成“可落地的后台任务”
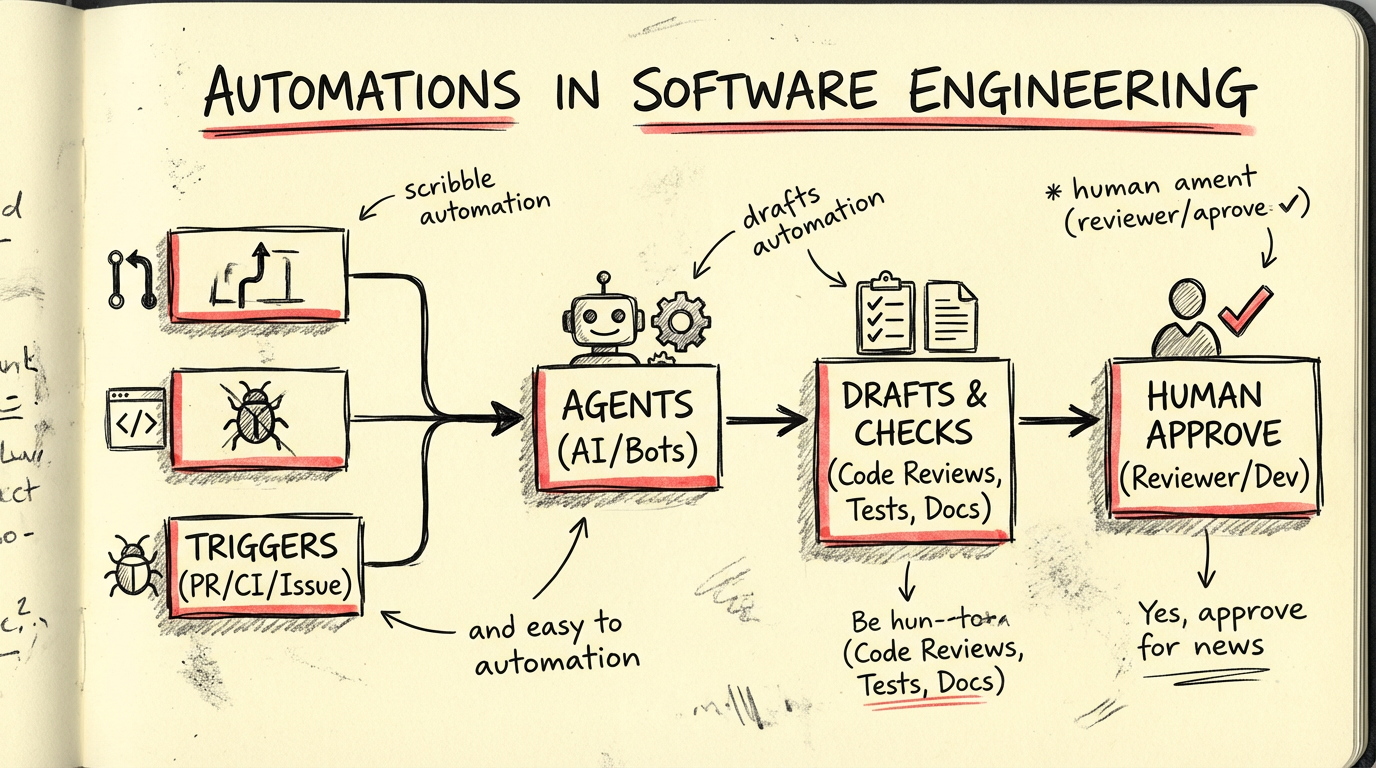
下面我把你给的能力列表,按工程团队常见的触发方式(commit/PR/CI/issue/weekly)重组一下,每个都补一段“怎么做成 demo”。
A. 提交与 Bug 扫描类
- 扫描最近提交,发现潜在 Bug 并给出最小修复建议
- 触发:每天 10:00 / 或 main 分支有新 merge
-
Demo:
1) 拉取近 24h commits(或从上次运行到现在)
2) 只针对高风险文件(auth、payment、migration、config)做静态扫描
3) 输出:风险点 + 最小修复 patch + 验证步骤(单测/回归点) -
识别未覆盖路径,补充测试并用 $yeet 辅助草稿 PR
- 触发:PR 打上 "needs tests" label
- Demo:
1) 解析 diff 找到新逻辑分支
2) 在 test suite 里定位最邻近的测试文件
3) 生成“最小覆盖”的测试用例 + 运行命令
B. PR 汇总与发布说明类
- 从合并的 PR 自动生成每周发布说明(含链接)
- 触发:每周五 17:30
-
Demo:
1) 拉取本周 merged PR
2) 以用户价值/风险维度分组(feature/fix/chore/security)
3) 输出 release notes 草稿,并要求每条都能回链到 PR -
用本周亮点与关键 PR 链接更新 changelog
- 触发:release 分支准备打 tag
- Demo:
1) 生成 changelog patch(只修改 CHANGELOG.md 某个版本区块)
2) 如果有 migration/flag 变更则自动提醒
C. CI/质量与性能类
- 总结 CI 失败与 flaky tests 并给出修复建议
- 触发:CI 失败时 / 每天早上一次
-
Demo:
1) 收集失败 job + 最近 N 次失败历史
2) 按根因聚类(依赖下载、并发、超时、随机性)
3) 输出“先修哪三个最划算”+ 最小改动建议 -
对比基准/trace,提前发现性能回退
- 触发:性能基准 job 完成
- Demo:
1) 读取基准数据(json/trace)
2) 检测关键指标回退阈值
3) 输出定位路径:最可能的 commit/PR + 复现步骤
D. 依赖与生态漂移类
- 检测依赖与 SDK 漂移并提出最小对齐方案
- 扫描过期依赖并提出安全升级方案(最小改动)
- 触发:每周一次
- Demo:
1) 生成依赖差异报告(当前 vs 推荐区间)
2) 标注 breaking risk
3) 给出“分两步走”的最小升级策略
E. 周报/晨会/团队协作类
- 总结昨天的 Git 活动用于晨会
- 触发:每天 9:20
-
Demo:
1) 汇总昨日 commits/PR/issue
2) 输出 standup 三段式:昨天/今天/阻塞 -
按成员与主题总结上周 PR 并突出风险点
- 综合本周 PR、发布、事故与评审生成周报
- 触发:每周一次
- Demo:
1) 把事实(链接/ID)与观点(风险评估)分开
2) 形成“管理者可读”的一页摘要
F. Issue 分诊类
- 新 Issue 分诊:推荐负责人、优先级与标签
- 触发:新 issue 创建
- Demo:
1) 从历史 issue/PR 找相似问题
2) 推荐 owner(不是指派)
3) 输出优先级建议 + 需要补充的信息清单
G. 发布前核对与文档维护类
- 发布打 tag 前检查 changelog、迁移、feature flag 与测试
- 触发:准备 tag
-
Demo:
1) 逐项核对(changelog / migrations / flags / tests)
2) 缺一项就阻断,并给出补齐路径 -
更新 AGENTS.md,补充新发现的工作流与命令
- 触发:每周一次 / 或 PR review 中出现新命令
- Demo:
1) 从 PR 评论、CI logs、脚本中抽取常用命令
2) 提交一个文档 PR(明确变更来源)
我补充的 5 个“最像样”的 Automations Demo(可以拿来当团队样板)
这部分是“我的延伸”,不是 OpenAI 页面原文。
Demo 1:24h 风险提交雷达(Risky Commits Radar)
目标:每天只给你 3 条最值得看的改动。
- 输入:近 24h commits + 文件路径 + 变更规模
- 输出:Top3 风险点 + 建议验证项(单测/压测/灰度)
- 关键:必须可解释(为什么它危险)
Demo 2:CI Flake 归因聚类器(Flake Clusterer)
目标:把 50 条失败日志压缩成 3 类根因。
- 输入:最近 N 次失败日志 + job metadata
- 输出:根因分组 + 每组一个“最小修复”
Demo 3:Release Notes “双通道”生成
目标:同时满足“用户可读”和“工程可追溯”。
- 通道 A(外部):用户收益语言
- 通道 B(内部):PR 链接 + 风险点 + 迁移注意事项
Demo 4:依赖漂移的“最小对齐计划”
目标:不追最新,只追安全。
- 第一步:对齐 minor/patch
- 第二步:单独开 breaking 升级项目
Demo 5:Standup 自动草稿(但必须带“阻塞提问”)
目标:让晨会从“汇报流水账”变成“解决阻塞”。
- 输出强制包含:
- 你今天最可能卡住的点是什么?
- 需要谁来帮你 unblock?
安全边界:哪些 Automations 我认为短期可以做,哪些不该做
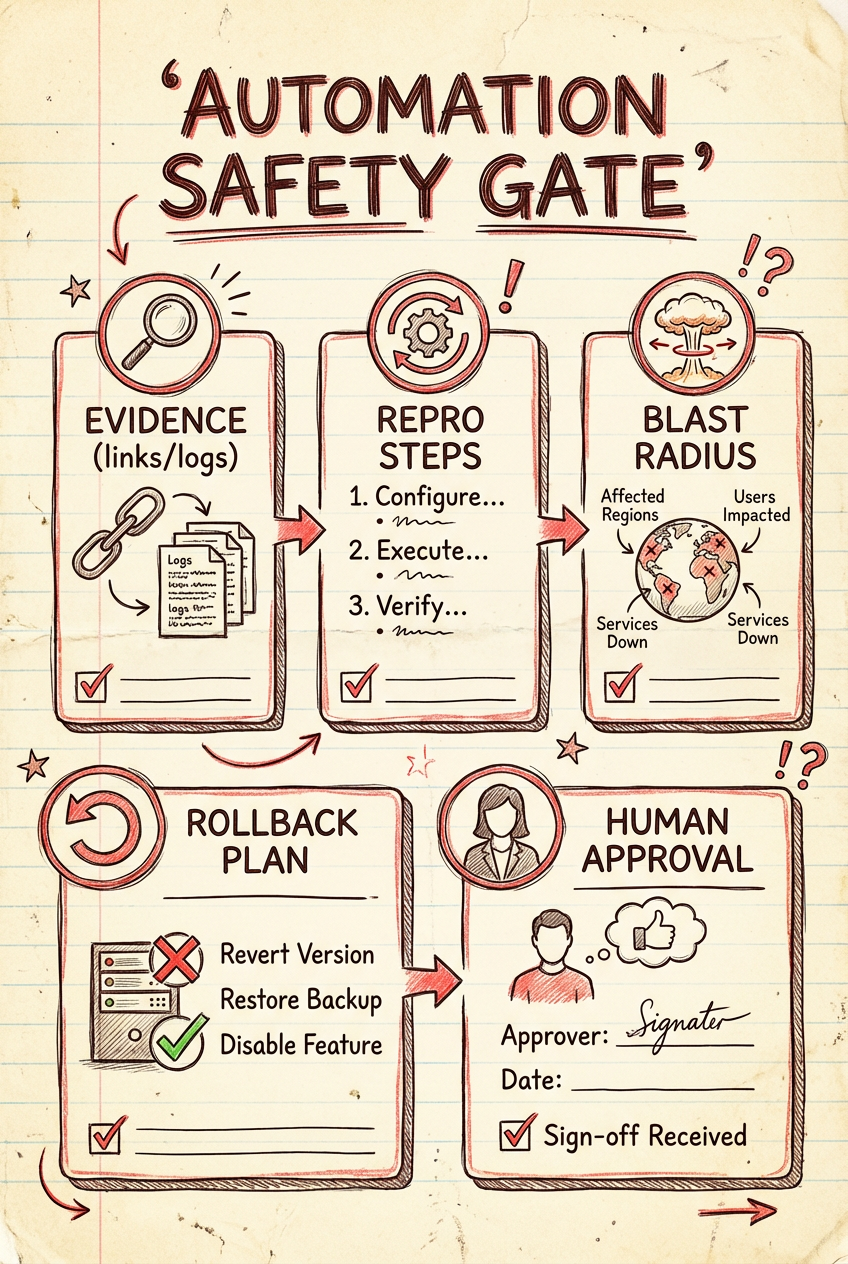
短期可以做(收益高、风险可控)
- 报告类:release notes、weekly update、changelog 草稿
- 归因类:CI failures 聚类、flake 趋势
- 发现类:依赖漂移、风险提交提示(但不自动 merge)
需要谨慎(很容易“看起来对,其实错”)
- 自动生成“修复 patch”并直接提 PR
- 自动修改生产配置/feature flag
- 自动关闭 issue / 自动下结论
我的建议是:
- 默认只生成草稿与建议
- 真正落地动作(merge / deploy / config change)必须有人类批准
结尾:如果你今天就想把 Codex 的 Automations 用起来,我建议从这一步开始
给团队一个“最小可用”的 Automations 版本:
1) 选一个高频痛点:CI flaky / release notes / 依赖漂移 三选一
2) 只做“收集→聚类→生成草稿”,不做自动执行
3) 强制输出可验证信息:链接、命令、复现步骤
4) 每周复盘一次:哪些建议真的帮你省了时间?哪些在制造噪音?
当 Automations 不再是“酷炫演示”,而是能稳定地帮你吞掉杂活,它才算真正进入工程体系。