Anthropic 五月十四号发了一篇长文,叫《How Claude Code works in large codebases》,是他们《Claude Code at scale》系列的第一篇。这是官方第一次系统化地把"大型代码库部署 Claude Code"的成功模式写出来——七个构件、搭建顺序、组织答案、加上他们替几十家头部客户落地后总结的反复出现的踩坑。
我把原文从头到尾看了两遍,对照我们团队过去半年在私有化云平台、Obsidian 知识库、blog 发布链路三处用 Claude Code 的实战,发现至少有六处是英雄所见略同——也就是说,无论你是在多语言 monorepo 里写 C++,还是在写一个不算"代码库"的知识库,真正决定 Claude Code 工作质量的不是模型,而是模型周围那套东西。 Anthropic 给它起了个名字,叫 harness。
下面这篇,是把原文核心论点拆开,套上我们自己的实战和过去几个月在 wiki 里沉淀的相关材料,给出一个团队层面的落地清单。
五个要点先拿走
- agentic search(遍历 + grep + 跟引用)在活跃的大型代码库里,会击败 RAG embedding 索引——embedding pipeline 永远跑不过 commit 速度
- harness 对 Claude Code 效果的影响 ≥ 模型本身。换句话说,配置的好坏比换不换 Opus 重要
- CLAUDE.md 是 router,不是图书馆。200 行硬上限。指针 + 致命陷阱,其它什么都不放
- Hooks 真正高价值的用法不是防呆,是让 setup 自演化——session 结束时反思并提议更新 CLAUDE.md
- 给一代模型补的拐杖,下一代模型来了会变成枷锁。配置必须每 3-6 个月做一次 ablation
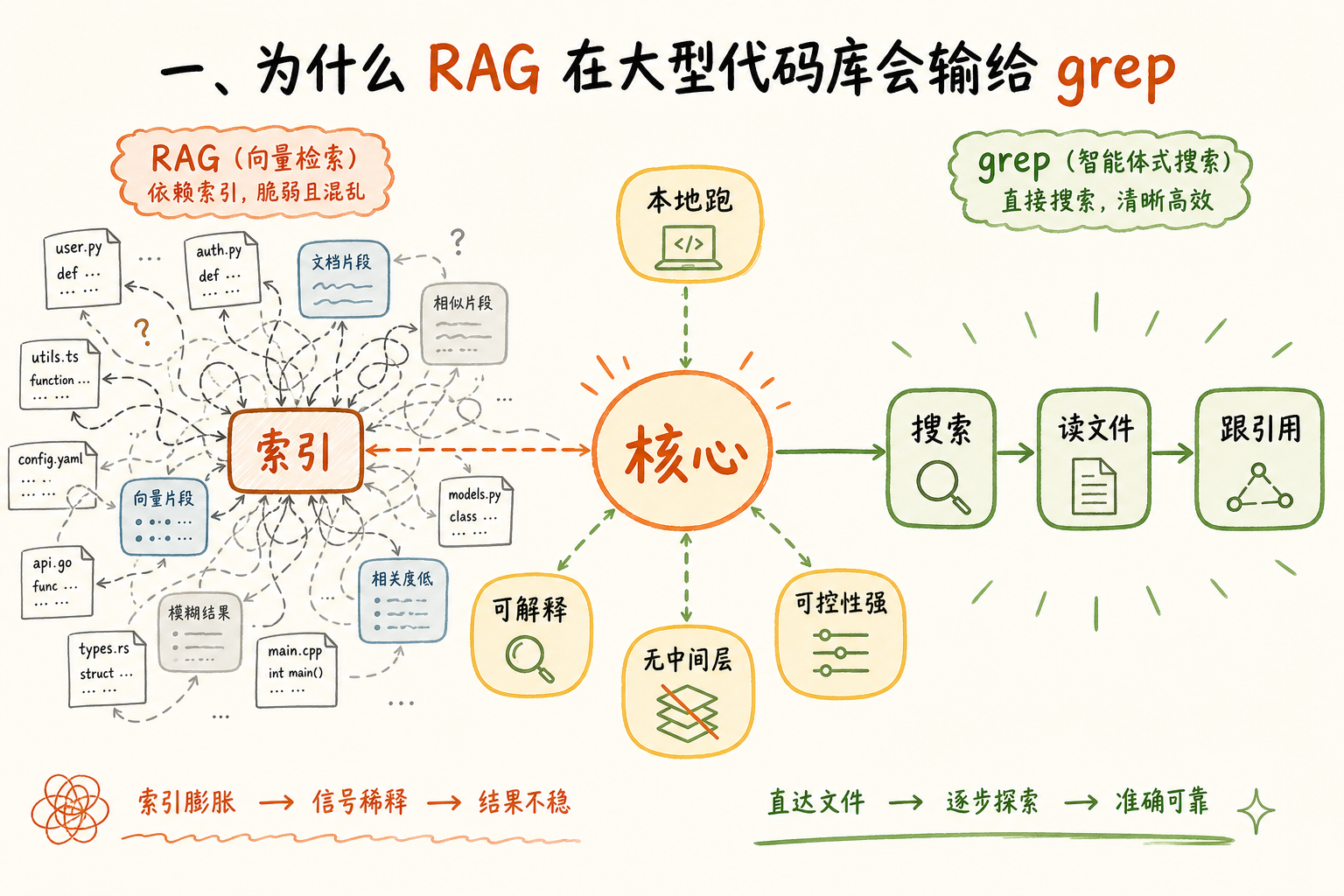
一、为什么 RAG 在大型代码库会输给 grep
很多公司在做"AI 代码助手"的第一反应是:建一个全代码库的 embedding 索引,查询时检索相关片段,喂给模型。听上去很合理。规模一上去就开始崩。
Claude Code 走的是另一条路:像工程师一样工作。遍历文件系统、读文件、grep、跟引用。完全本地运行,不需要服务端索引。Anthropic 把这种模式叫 agentic search。
两种模式在大型代码库里的差异:
维度
RAG embedding 索引
agentic search(Claude Code)
工作方式
预先把全库 embed,查询时检索片段
实时从文件系统出发,grep + 读文件 + 跟引用
失效场景
函数两周前已改名 / 模块上 sprint 已删除
因为读的是 live filesystem,不会失效
维护成本
embedding pipeline 必须跟上 commit 速度
零索引成本
准确性来源
向量相似度(可能召回过期信息)
工程师的导航直觉 + 符号精确性
上限
索引滞后即崩
受限于初始上下文够不够 Claude 知道"该去哪儿找"
代价不是零。agentic search 的代价是:Claude 必须有足够的初始上下文知道去哪儿找。你扔给它"找所有匹配某模糊模式的地方",在十亿行代码库里它会先把 context window 撑爆。
所以 RAG 的工程问题被换成了另一个工程问题:怎么让 codebase 对 Claude 可读。这正好是 harness 的活。
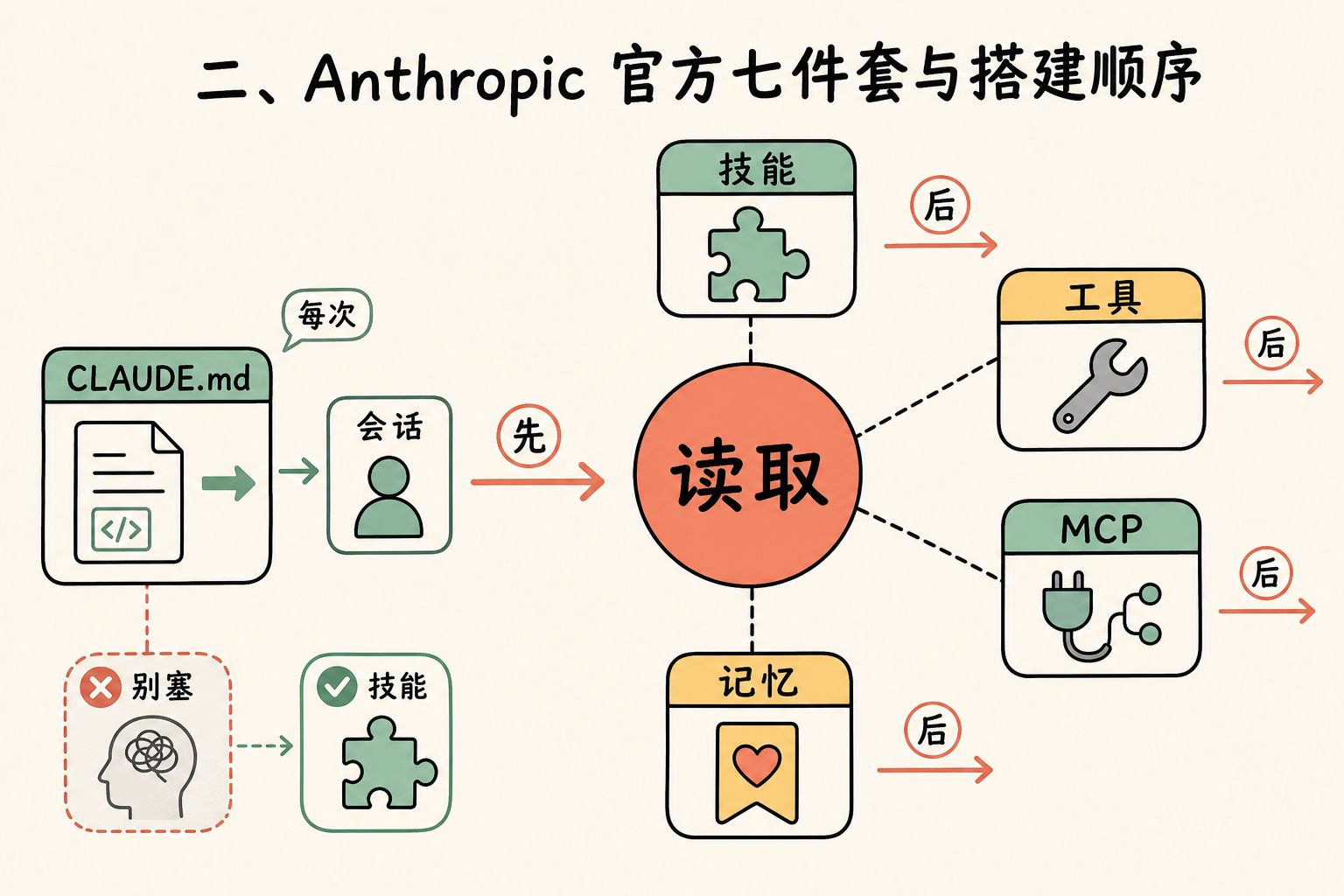
二、Anthropic 官方七件套与搭建顺序
把 harness 拆开是五个扩展点加两个能力,按搭建顺序排:
构件
是什么
何时加载
适合做什么
最常见的误用
CLAUDE.md
自动读取的上下文文件
每个 session
项目约定 + 代码库知识
把可复用专家知识塞进来(该写成 skill)
Hooks
关键时刻触发的脚本
事件触发
一致性自动化 + 捕获 session 学习
用 prompt 做本该自动跑的事
Skills
针对某类任务打包的指令
按需触发
跨 session/项目复用的专长
全塞进 CLAUDE.md
Plugins
打包 skills+hooks+MCP
配置后常驻
把可用的 setup 分发到全组织
让好 setup 停留在部落里
LSP(经 plugin 层)
语言服务器实时智能
配置后常驻
符号级导航 + 类型语言错误检测
以为它自动有
MCP servers
连接外部工具 / 数据
配置后常驻
让 Claude 触达内部系统
基础没做好就先做 MCP
Subagents
独立 Claude 实例
调用时
拆分探索/编辑、并行
在同一 session 里同时探索 + 编辑
顺序很重要。先把 CLAUDE.md 做对,再加 Hooks 做自动化,等单 session 用顺了再上 Skills 做复用,最后用 Plugin 打包分发。绝大多数团队会跳过前两步直接做 MCP,然后发现"为什么 AI 还是找不到东西"——基础没搞好。
Subagent 不算扩展点而是一种委托能力。read-only subagent 先映射一遍子系统并把发现写入文件,然后让主 agent 带着完整全景去做编辑。这一招在我们团队读私有化部署链路的时候试过,比单 session 来回切几次目录省 context 不止一半。
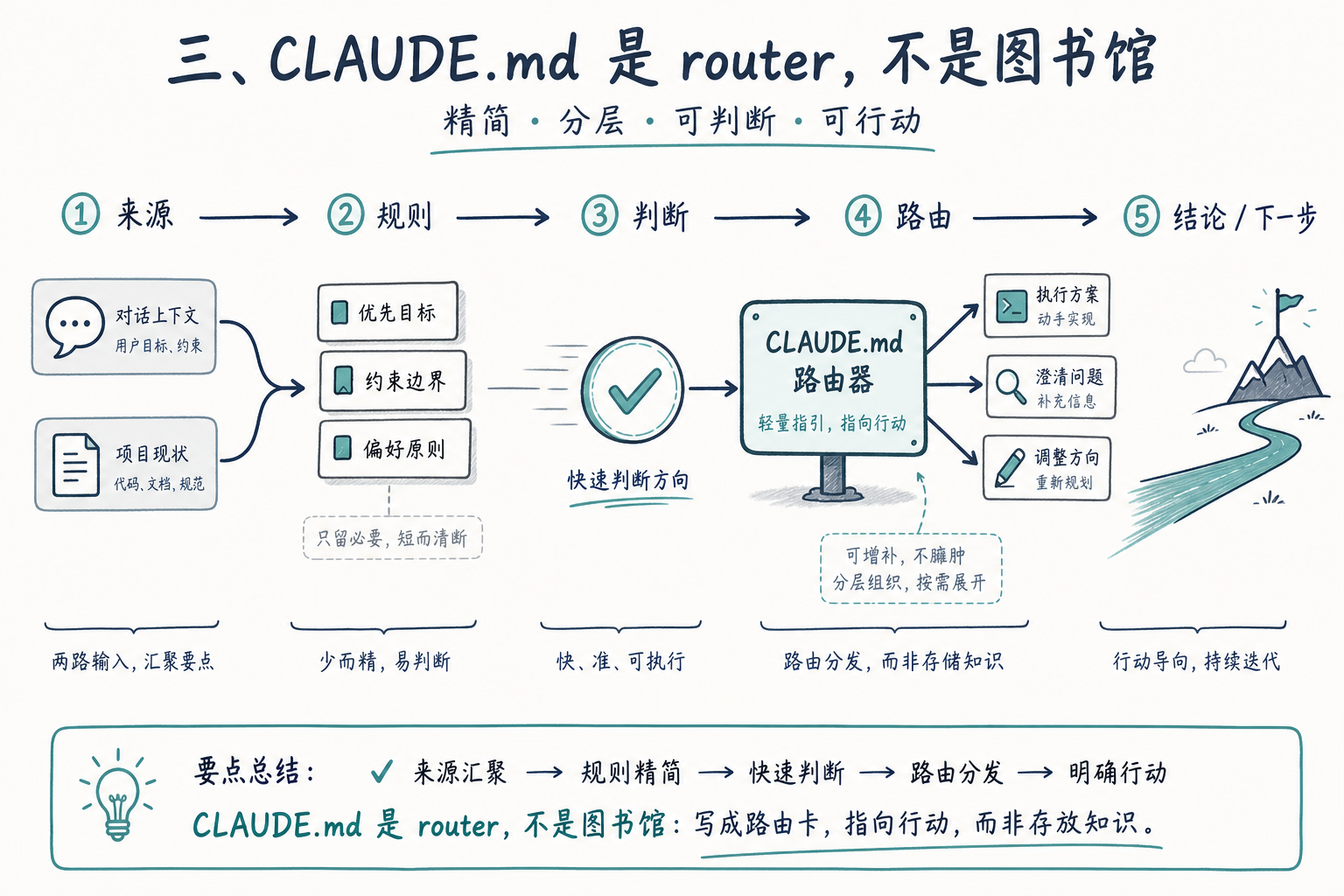
三、CLAUDE.md 是 router,不是图书馆
Anthropic 在原文里反复强调"keep CLAUDE.md lean and layered"。这个观点不是孤证。@vincemask 在 X 上总结的《写好 CLAUDE.md 的八条经验》是另一个独立来源,结论高度一致:
- 越短越好,200 行硬上限。Boris Cherny(claude-code-best-practice 作者)的原话
- CLAUDE.md 是指针不是图书馆,普通用户写知识梳理,顶级用户写 router
- 规则必须可被 5 秒判断符合:"写干净的代码"对 AI 等于没说,"用 named export 而不是 default export"才算
- "Do NOT introduce" 区块和 Tech Stack 同等重要——不写禁止清单,Claude 会"出于善意"引入它"知道"的最优方案,比如把你的 Zustand 项目改回 Redux
这里有个特别 Linus 的判断:规则必须可操作,不是可感受。一条规则如果能在五秒内判断代码是否符合,它就是工程化的规则;否则它就是装饰。
我们 Obsidian 知识库的 CLAUDE.md 现在大约 200 行(在范围内但仍偏知识梳理),实际承担的角色就是 router:
- 指向
AKSOUL.md—— 价值观与判断准绳 - 指向
wiki/index.md—— 知识库结构 - 指向
.claude/commands/里的ingest / distill / query / lint / synthesis—— 流程 - 顶部留一段"绝对禁止"硬约束(不许 rm、不许 sed -i、不许动 .obsidian/)
这套结构其实就是 Anthropic 原文说的"分层 CLAUDE.md + 路径绑定的 skills + hooks 做强制"。
Anthropic 的进阶建议是:在子目录而非仓库根 init。Claude 自动向上走目录并合并所有遇到的 CLAUDE.md,所以根级永远不会丢。在 monorepo 里这一条尤其值得,因为根级 CLAUDE.md 一旦塞进所有子目录的细节就会迅速膨胀。
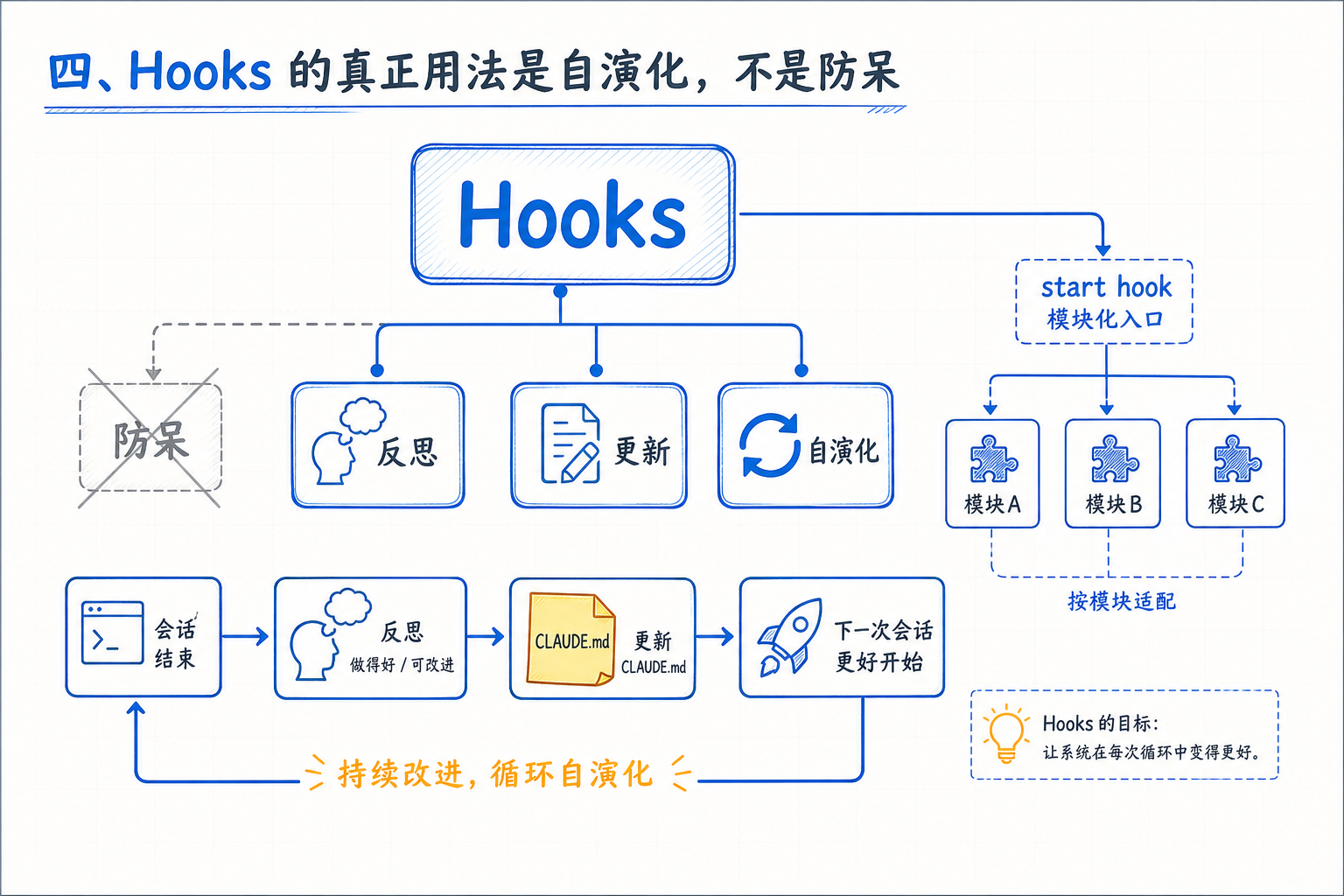
四、Hooks 的真正用法是自演化,不是防呆
我以前对 hooks 的理解就是"加一个 prettier 强制跑"。原文给了一个完全不同的视角:
Most teams think of hooks as scripts that prevent Claude from doing something wrong, but their more valuable use is continuous improvement.
stop hook 可以在 session 结束时反思这一轮发生了什么,并提议更新 CLAUDE.md——趁 context 还热。这是把 setup 变成一个自演化系统。
start hook 可以按模块动态加载团队上下文,每个开发者一进入对应目录就拿到正确的设置,不用每个人手动配。
我们的 .claude/commands/distill 其实在做类似的事:把日记蒸馏成 wiki/analysis/。还可以更进一步——session 结束时自动 distill 出"今天哪些规则没被遵守、要不要写进 CLAUDE.md"。这是 Anthropic 在原文里没明说但暗示的方向。
[[2026-05-16-Agent-Hooks确定性控制]] 里我们记过一个判断:写在 CLAUDE.md 里的规则是"请记住";配了 Hook 的规则是"你必须"。 这正好把 Anthropic 原文里"hooks enforce the rules deterministically and produce more consistent results than relying on Claude to remember an instruction"翻译成了一句中文。
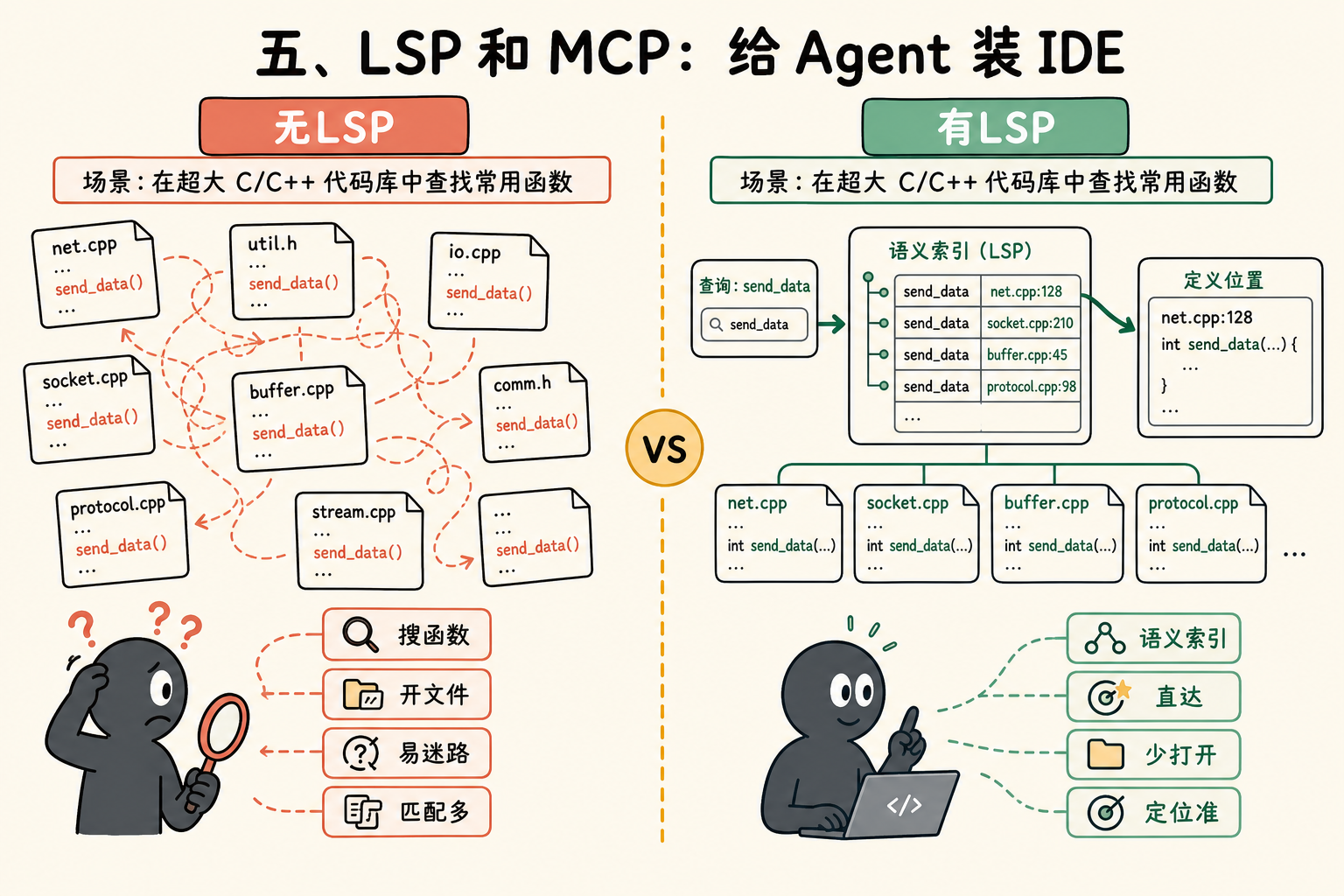
五、LSP 和 MCP:给 Agent 装 IDE
原文有句话我画了重点:
One enterprise software company we worked with deployed LSP integrations org-wide before their Claude Code rollout, specifically to make C and C++ navigation reliable at scale.
这家公司把 LSP 当成 Claude Code 上线的前置条件。原因很简单:在 C/C++ 这种类型语言、千万行级别的代码库里,grep 一个常见函数名会返回上千个匹配,Claude 要打开几十个文件才能搞清楚哪个才是要找的那个。LSP 返回的是真正指向同一符号的引用,过滤动作在 Claude 读任何文件之前就完成了。
多语言 monorepo 里,LSP 是 ROI 最高的投资之一。它不是"提升体验",它是"让大规模导航成为可能"。
MCP 是另一回事。它解决的是"Claude 怎么触达内部系统"——ticketing、analytics、内部文档、结构化搜索。最成熟的团队会把"结构化搜索"这一动作专门做成 MCP tool,让 Claude 直接调用,而不是让它瞎 grep。
原文有一个关键警告:别在基础没做好之前先做 MCP。这一条我们也踩过。Hermes 接 Grok 那次([[2026-05-17-Hermes升级与Grok全家桶接入]])就是 MCP 在前、基础在后的反面教材——先解决"它能不能找到对的东西",再解决"它能不能调外部服务"。
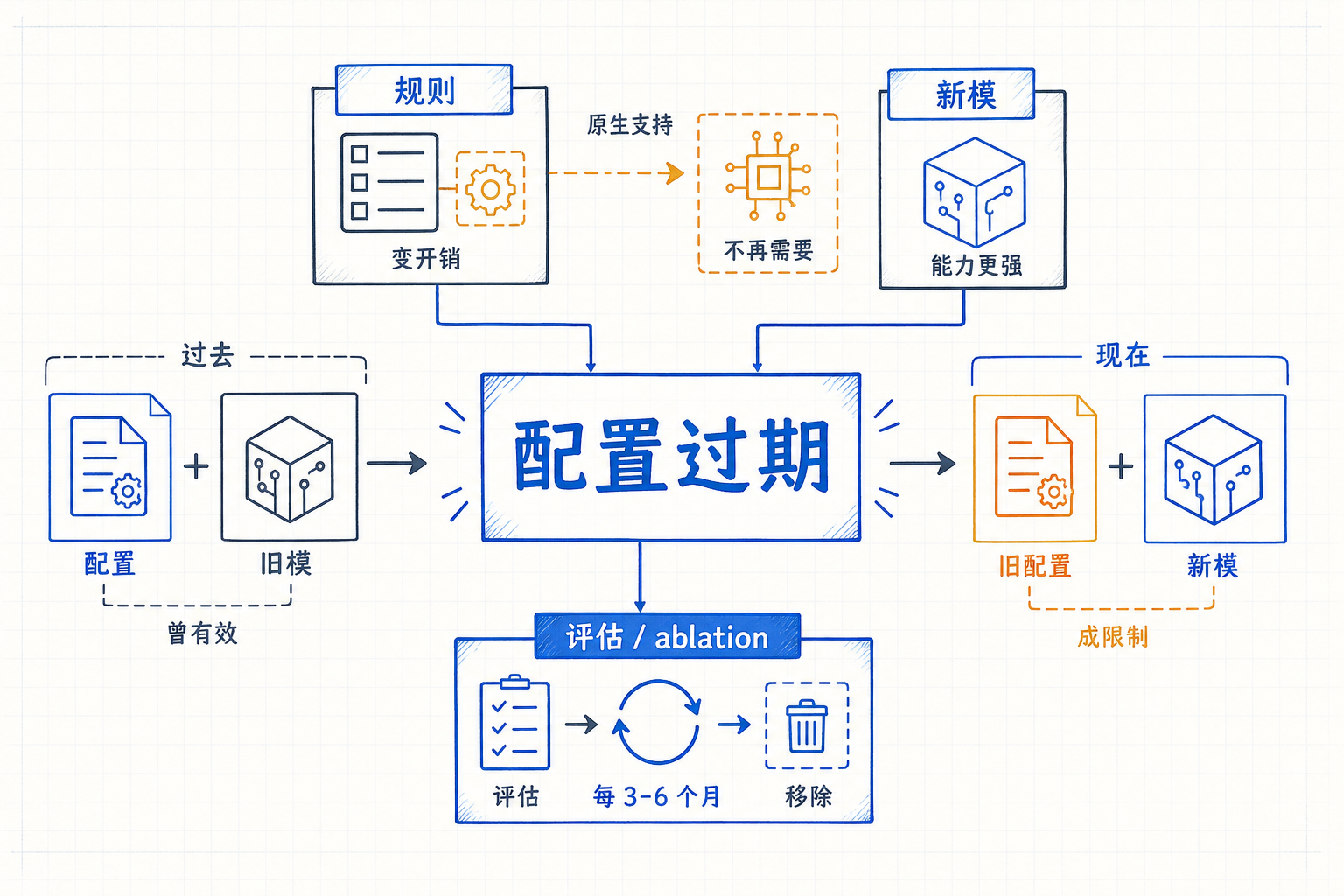
六、配置会过期:每 3-6 个月做一次 ablation
这一节是原文里最容易被忽略,但工程上最重要的一节。原文的原话:
As models evolve, instructions written for your current model can work against a future one.
举的例子很犀利:一条让 Claude "把每次重构拆成单文件改动"的 CLAUDE.md 规则,对早期模型是救命稻草,对新模型反而限制了它做跨文件协调编辑的能力。一个为了在 Perforce 代码库里强制跑 p4 edit 写的 hook,在 Claude Code 添加了原生 Perforce 支持之后就变成纯粹的开销。
[[2026-05-08-停止为AI设计Harness]] 里我们记录过 Kangwook Lee 的 Three Regimes 框架——固定 harness 看模型能力时,每条 harness 规则对每个任务都是一道阈值。模型能力穿过阈值之后,规则要么没用,要么有害。手搓 harness 的 ROI 随模型升级单调衰减。
实操含义就一条:每 3-6 个月做一次 ablation。把每条规则拿出来问:
- 这条规则当初是补哪个模型缺陷的?
- 缺陷还在吗?换 Opus 4.7 还在吗?
- 不在了,删
- 还在但只在边界场景出现,移到 skill
- 还在且高频,保留
任何大模型版本发布后,如果觉得效果"平台化"了,也立刻做一次 ablation。
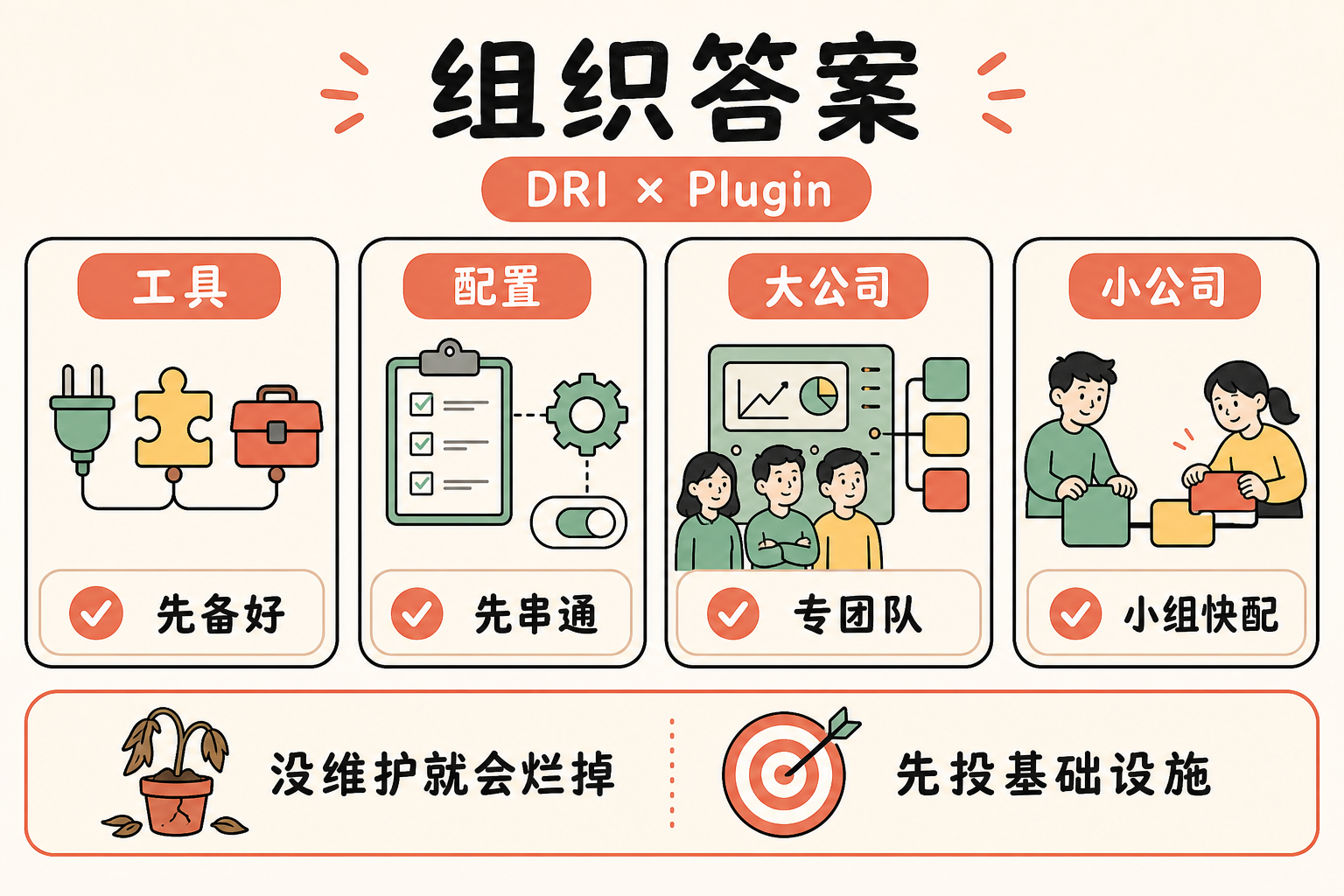
七、组织答案:DRI 与 Plugin Marketplace
技术配置再好,没人维护也会烂掉。Anthropic 原文里花了一整节讲组织答案,结论很直接:那些 rollout 扩散最快的公司,在大面积访问之前就有专门的基础设施投入。
形态有两种:
- 大公司:一支专门管 AI 编程工具的团队,rollout 之前 plugin 和 MCP 已经全部就绪
- 小公司:一两个人组成的小组,提前把 plugin 串起来,让开发者上手即用
正在出现的一个新角色叫 Agent Manager——PM/Engineer 混合,专管 Claude Code 生态。这个角色目前大多挂在 Developer Experience 团队下面。
对没有专职团队的公司,最低限度需要一个 DRI:一个对 Claude Code 配置有决策权和维护责任的人。settings、permissions policy、plugin marketplace、CLAUDE.md 规范——这些不能让它们没有 owner。
我们团队的 plugin 模式那次 5 天复盘([[2026-05-18-Plugin模式发布全链路修复]])就是这个论点的真实案例。Plugin 的窗口期从我最初判断的 3-6 个月,现在缩短到 1-3 个月——Anthropic 在 v2.1.108 里一周内把 marketplace 一级化、依赖图语义、token 计量全部做完了。plugin marketplace 是 Anthropic 给"好 setup 别停留在部落里"这个组织问题的技术答案。
但是技术答案不能替代组织答案。没有 DRI 去筛、去更新、去 evangelize,marketplace 就只是一堆乱码 plugin。两者必须同时存在。
八、给团队的七个立即可执行动作
读完不动手等于没读。下面七条不用问任何人,今天就能做:
- 把 CLAUDE.md 砍到 200 行以内——超出的部分大多是知识梳理,应该移到 wiki 里只保留链接
- 加 "Do NOT introduce" 区块——至少列三个项目已经放弃的技术栈/库,防止 Claude "出于善意"复活它们
- 把每条模糊规则改成 5 秒可判断——"写干净的代码"删掉,"组件不超过 200 行"留下
- 在敏感目录(auth / payments / infra)加本地 CLAUDE.md——只写安全红线和已知陷阱
- 配一个 stop hook——在 session 结束时把"这一轮哪些规则没被遵守"写到一个日志文件里,每月人工 review 一次
- 多语言代码库上 LSP——优先 C/C++/Java/TypeScript,单语言项目可以暂缓
- 设一个 DRI——一个人对 Claude Code 配置负责,不要让它没有 owner
这七条没一条需要新预算,全部是工程纪律。
收束
Linus 那句"good programmers worry about data structures and their relationships"放到 Agent 时代,可以改写成:
good engineering teams worry about their harness and its relationships.
模型会一直变,新版本一个接一个发。但 harness 的搭建顺序、自演化机制、ablation 节奏、组织 DRI——这些工程纪律的半衰期比模型长得多。
Anthropic 原文最后一句话写得很克制:
Any remaining complexity requires judgment specific to your codebase, tooling, and organization.
剩下的复杂度要靠你自己判断。下次配置审查就放在三个月后。
原文:How Claude Code works in large codebases: Best practices and where to start | Anthropic Blog | 2026-05-14
作者:toy