Artificial Analysis 最新战力榜揭示了一个被忽略的真相——OpenAI 正在失去"全能王"的宝座。
TL;DR
- GPT-5.2 以 51 分称霸综合智力榜,但领先优势正在收窄
- 国产黑马杀入:GLM-4.7 在智能体(Agent)赛道位列全球第三
- 格局裂变:没有一款模型能"通吃"所有场景,选型策略比盲目追捧更重要
一、御三家的统治:但裂缝已经出现
Artificial Analysis 的 Intelligence Index(综合智力指数)揭晓了 2025 年末的 AI 实力分布。
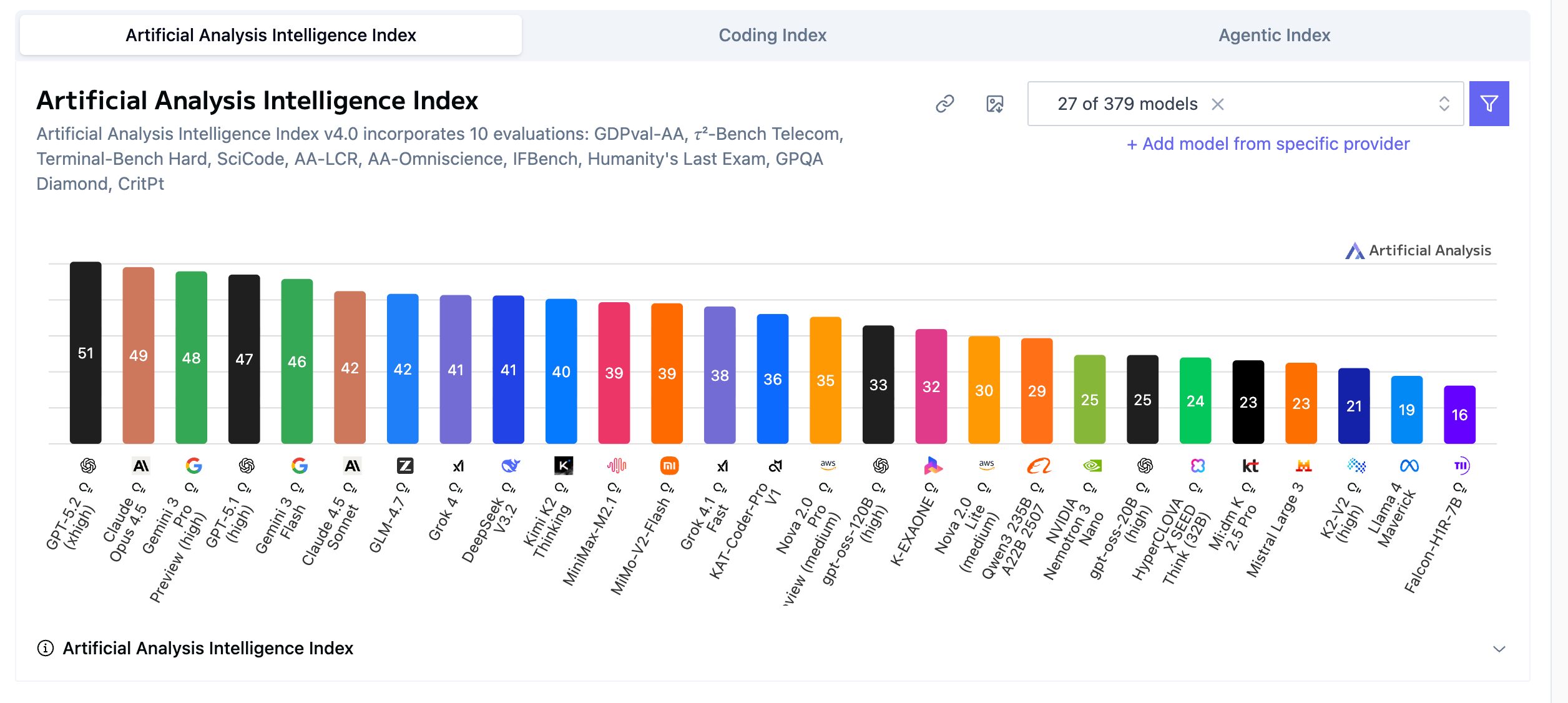
霸主依旧,但优势不再碾压
模型
综合智力分
备注
GPT-5.2
51分
断层领先,稳坐头把交椅
Claude Opus 4.5
49分
一步之遥,Coding 更优雅
Gemini 3 Pro Preview
48分
Google 终于找回节奏
DeepSeek V3.2 / GLM-4.7
41分
国产双雄守住第二梯队前列
关键洞察:GPT-5.2 的 51 分和 Claude 的 49 分之间,只差两道算术题。这意味着——综合智力的军备竞赛,正在触及天花板。
纯粹靠"聪明"比拼的时代,即将结束。🎯
二、被低估的战场:Agent 能力
如果说"智力"是 AI 的智商,那"Agent 能力"就是它的情商+执行力。
Agentic Index(智能体指数)代表着让 AI 真正"干活"的能力——调用工具、拆解任务、持续执行。
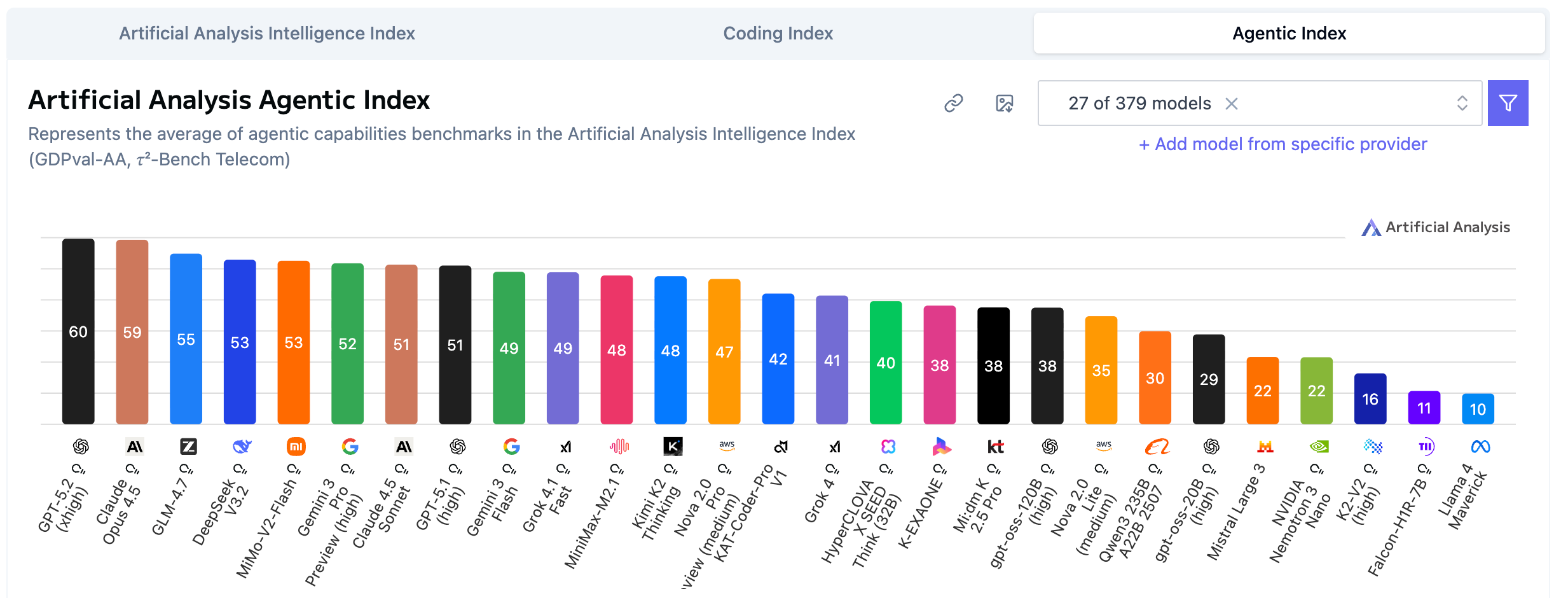
🇨🇳 国产模型的逆袭时刻
排名
模型
Agent 分
亮点
🥇
GPT-5.2
57分
全能型选手
🥈
Claude Opus 4.5
56分
长任务稳定性最佳
🥉
GLM-4.7
55分
国产首次杀入前三!
4
DeepSeek V3.2
53分
性价比之王
4
MiMo-V2-Flash
53分
小米的秘密武器
反直觉的事实:在"干活"这件事上,GLM-4.7 已经超越了 Gemini 3 系列(52分)。
这不是刷榜,是战场选择的胜利。当硅谷巨头沉迷于参数竞赛时,国产团队选择了更务实的方向——让 AI 解决真实问题,而不是通过考试。
💡 观点:2026年,选模型不再看"谁更聪明",而是看"谁能帮我干完这件事"。
三、代码能力:护城河依然坚固
Coding Index(代码能力指数)的格局相对固化,OpenAI 和 Anthropic 形成双寡头。
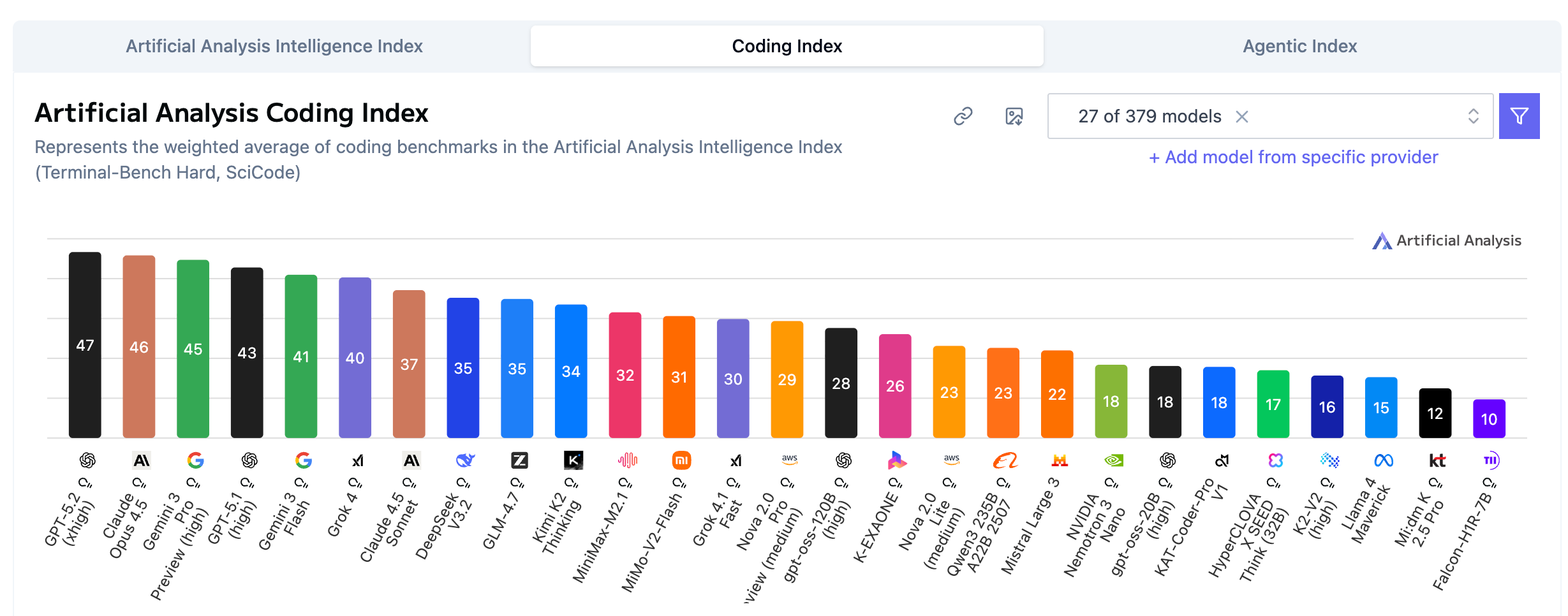
模型
代码分
分析
GPT-5.2
47分
逻辑一致性最强
Claude Opus 4.5
46分
代码审美最优雅
Gemini 3 Pro
38分
与头部存在代差
开源最佳(Llama 4)
15分
巨大鸿沟
残酷现实:代码生成需要极强的逻辑一致性和超长上下文把控,这是闭源巨头的护城河。开源模型和新锐玩家,短期内难以突破。
如果你是开发者,Coding 场景仍建议首选 Claude 或 GPT——这不是立场,是效率。
四、2026年选模型的正确姿势
不同场景的最优解
场景
推荐模型
理由
日常问答/通用任务
GPT-5.2
综合实力无短板
代码开发/审查
Claude Opus 4.5
代码美学 + 长上下文
自动化工作流/Agent
GLM-4.7 / DeepSeek V3.2
高性价比 + 工具调用强
成本敏感场景
DeepSeek V3.2
价格仅为 GPT 的 1/10
三个值得关注的趋势
- 版本号大跃进:GPT-5、Claude 4.5、Gemini 3、Llama 4——我们正处于能力代际跃迁的前夜
- 偏科成为常态:没有模型能全方位碾压,组合使用才是最优策略
- Agent 是新战场:谁能让 AI 真正"干活",谁就掌握下一个十年
我的判断
GPT-5.2 的霸榜,是意料之中的结果。但真正值得关注的不是谁第一,而是第二梯队的崛起速度。
当 GLM-4.7 能在 Agent 任务上与 Claude 掰手腕时,当 DeepSeek 能以十分之一的价格提供八成的能力时——游戏规则正在改变。
未来属于那些不追求"全能",而是把一件事做到极致的模型。
就像 Linux 战胜了"功能更全"的商业操作系统一样。🐧
数据来源:Artificial Analysis Index v4.0
注:部分模型可能为预测型号或预览版本,实际性能以官方发布为准。