你可能在某篇文章里看到过这样一段代码——只有四行,复制粘贴到浏览器控制台,整个网页就变成了一个 AI 助手的操作台:
const script = document.createElement('script');
script.src = 'https://registry.npmmirror.com/page-agent/1.5.6/files/dist/iife/page-agent.demo.js';
script.crossOrigin = 'true';
document.head.appendChild(script);
等一下,这到底在做什么?
表面上看,它只是动态加载了一个外部 JS 文件。但这四行代码的背后,藏着一个完整的浏览器原生 AI Agent 框架——3000+ 行精心设计的架构,涵盖 LLM 调用、DOM 智能感知、交互操作引擎、UI 面板和 WebGL 动效渲染。
今天我把源码 逐层拆开,带你看看这个"四行代码"的真实面目。
项目概况:阿里巴巴出品的浏览器 AI Agent
page-agent 是由阿里巴巴开源的 JavaScript 页面内 AI Agent,定位很明确:用自然语言控制 Web 界面。
- 📦 GitHub 仓库:alibaba/page-agent(⭐ 5.6k+ stars,434 forks,712 commits,MIT 协议)
- 🧩 Chrome 扩展:Page Agent Ext(1000+ 用户)
- 🌐 官方文档:alibaba.github.io/page-agent
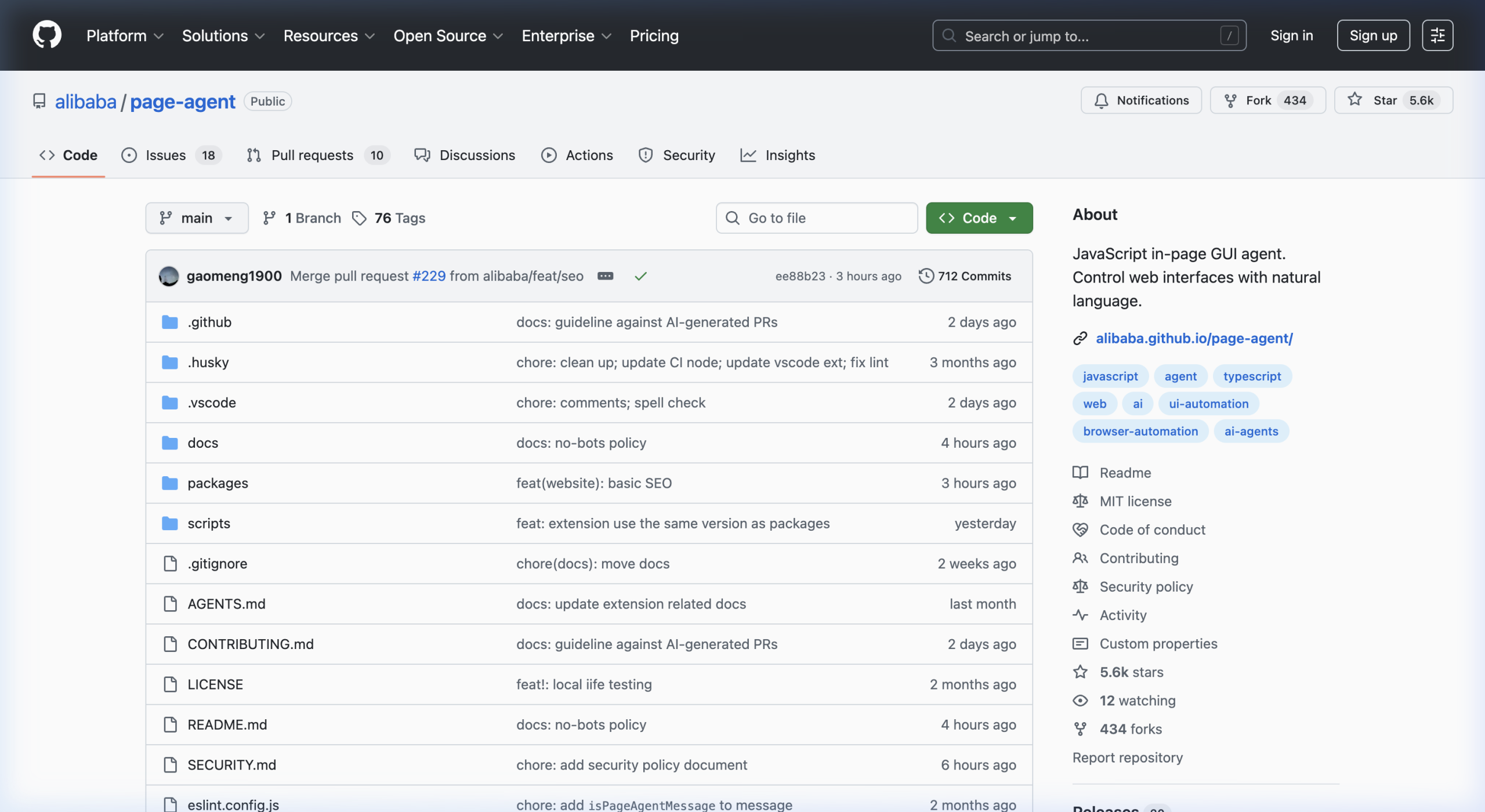
项目采用 monorepo 架构(packages/ 目录),包含核心库和 Chrome 扩展两部分。标签体系明确:javascript、agent、ai、browser-automation、ui-automation。
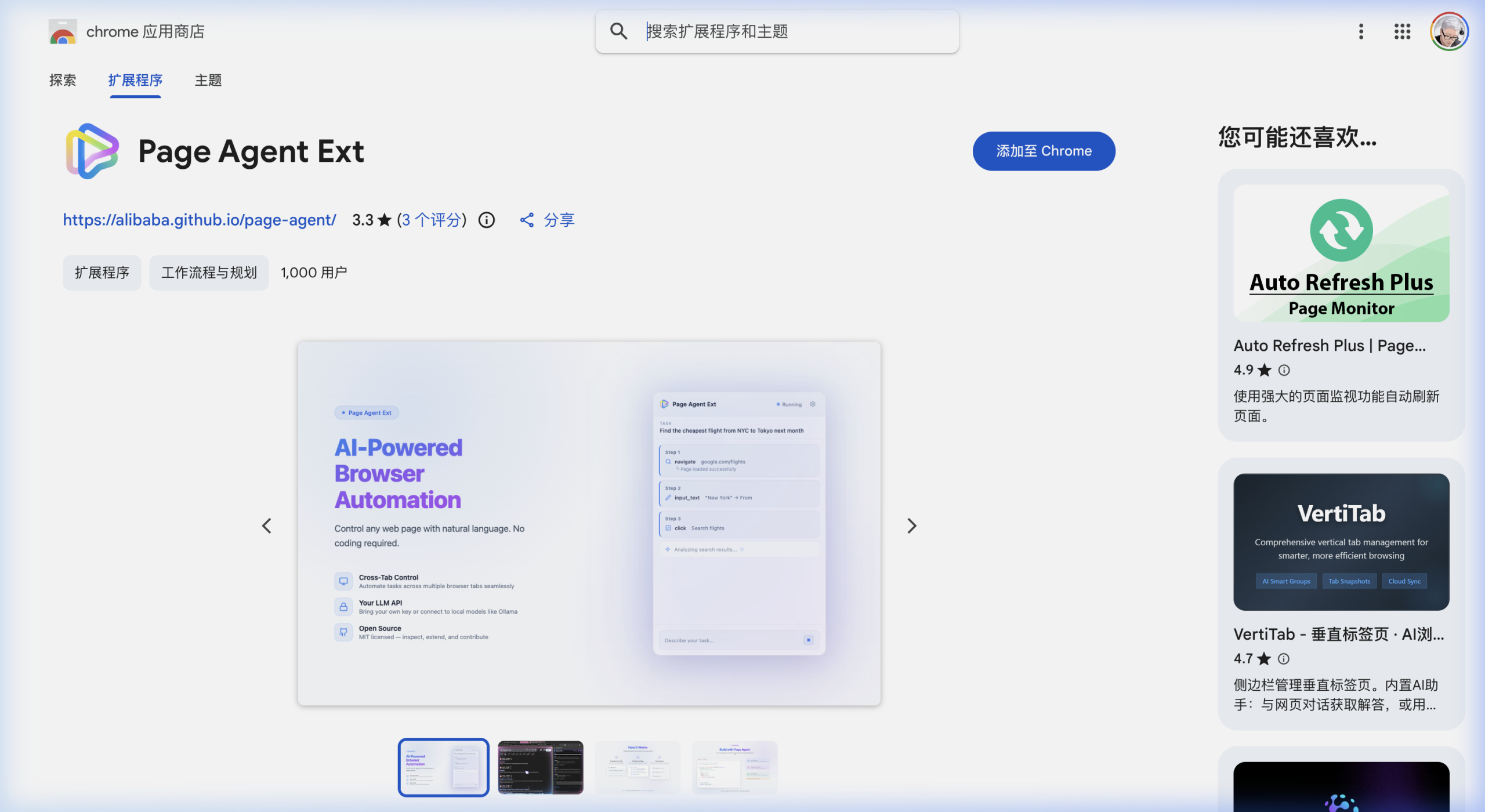
除了控制台注入 demo 脚本外,更推荐的使用方式是直接安装 Chrome 扩展 Page Agent Ext。配置好 LLM 的 Base URL、模型名和 API Key 后,就可以在任意网页上用自然语言下达指令了。
架构全景:五层金字塔
从源码中提炼出的完整架构如下:
┌─────────────────────────────────────┐
│ Layer 5: WebGL 动效渲染层 │
│ Motion / SimulatorMask / Shaders │
├─────────────────────────────────────┤
│ Layer 4: UI 面板层 │
│ Panel / I18n / Card Components │
├─────────────────────────────────────┤
│ Layer 3: Agent 核心调度层 │
│ PageAgentCore / LLM / Tool Router │
├─────────────────────────────────────┤
│ Layer 2: DOM 智能感知层 │
│ domTree / flatTreeToString │
├─────────────────────────────────────┤
│ Layer 1: 交互操作层 │
│ clickElement / inputText / scroll │
└─────────────────────────────────────┘
每一层都是独立的关注点,层间通过清晰的接口通信。这是教科书级别的分层设计。
Layer 1:交互操作层——让 AI 拥有手和眼
这一层解决的核心问题是:如何让代码像人一样操作网页?
点击:不是简单的 .click()
看看 clickElement 的实现,它有意思在于模拟了完整的人类点击序列:
async function clickElement(e) {
blurLastClickedElement(); // 1. 先释放上一个焦点
lastClickedElement = e;
await scrollIntoViewIfNeeded(e); // 2. 确保元素可见
await movePointerToElement(e); // 3. 移动虚拟光标到元素中心
// → 触发 PageAgent::ClickPointer 自定义事件
// 4. 按人类交互的真实顺序派发事件
e.dispatchEvent(new MouseEvent("mouseenter", ...));
e.dispatchEvent(new MouseEvent("mouseover", ...));
e.dispatchEvent(new MouseEvent("mousedown", ...));
e.focus();
e.dispatchEvent(new MouseEvent("mouseup", ...));
e.dispatchEvent(new MouseEvent("click", ...));
await waitFor(0.2); // 5. 模拟人类反应时间
}
为什么不直接调用 .click()?因为很多现代前端框架(React、Vue)的事件监听挂在合成事件上,简单的 .click() 可能触发不了。完整的事件序列是对浏览器事件模型的深刻理解。
输入:绕过 React 的值劫持
输入文本的实现更精妙。React 会劫持 input.value 的 setter,直接赋值不会触发状态更新。看看代码怎么解决的:
const nativeInputValueSetter = Object.getOwnPropertyDescriptor(
window.HTMLInputElement.prototype, "value"
).set;
// 对于普通 input,使用原生 setter 绕过框架劫持
nativeInputValueSetter.call(element, text);
// 然后手动触发 input 事件让框架感知变化
element.dispatchEvent(new Event("input", { bubbles: true }));
这段代码直接从 HTMLInputElement.prototype 上获取原生的 value setter,绕过了 React 的 Fiber 拦截。操,这写得真漂亮。
contentEditable 的特殊处理
对于富文本编辑器(TinyMCE 等),还有一套完全不同的逻辑:
if (element.isContentEditable) {
// 先发 beforeinput 询问是否可编辑
element.dispatchEvent(new InputEvent("beforeinput", {
inputType: "deleteContent"
}));
element.innerText = ""; // 清空
// 再插入新文本
element.dispatchEvent(new InputEvent("beforeinput", {
inputType: "insertText", data: text
}));
element.innerText = text;
}
三种输入方式(<input>、<textarea>、contentEditable)通过一个函数统一处理,没有多余的 if/else 链——这就是好品味。
Layer 2:DOM 智能感知层——把网页变成 AI 能读的文本
这是整个框架最核心、最复杂的一层。它要回答一个根本问题:AI 如何"看见"一个网页?
domTree:递归构建语义树
domTree 函数从 document.body 开始递归遍历整棵 DOM 树,但它做了大量智能过滤:
- 跳过不可见元素:通过
checkVisibility、offsetWidth/Height、computed style多维度判断。 - 跳过自身 UI:带
data-page-agent-ignore属性的元素直接忽略。 - viewport 裁剪:可配置只扫描视口范围内的元素,用
ClientRect做边界检测。 - Shadow DOM 穿透:自动递归进入
shadowRoot。 - iframe 内容穿透:在同源策略允许的范围内读取 iframe 文档。
交互元素识别:不止于标签名
isInteractiveElement 函数的判断逻辑极其丰富,它不只看标签名:
检查维度:
├── 语义标签:a, button, input, select, textarea, details, summary
├── ARIA 角色:role=button, role=menu, role=slider, role=combobox...
├── 光标样式:cursor: pointer → 可交互
├── contentEditable 属性
├── CSS 类名启发式:.button, .dropdown-toggle, .clickable
├── 事件监听器检测:onclick, getEventListeners()
├── data 属性:data-toggle, data-action
└── 可滚动容器检测:overflow: auto/scroll
看到没?它甚至尝试调用浏览器的 getEventListeners() API 来检测动态绑定的事件。这不是简单的 querySelectorAll('button'),而是接近人类视觉认知的"这个东西看起来能点"的判断。
flatTreeToString:把 DOM 压缩成 LLM 能理解的文本
[0]<a href="/home" role=link>首页 />
[1]<button aria-expanded=false>菜单 />
纯文本内容不包含索引
[2]<input type=text placeholder=搜索... />
[3]<div data-scrollable="top=0, bottom=1200">
每个可交互元素被赋予一个 [index],LLM 只需要说"点击 [1]"就能操作。文本节点保留语义上下文,但不编号。属性做了智能裁剪——重复的、和文本内容一致的 aria-label 会被自动去除。
Layer 3:Agent 核心调度层——大脑
工具注册表
Agent 内置了 8 个工具(Tool),全部通过一个 Map 注册:
工具
作用
输入
done
任务完成
text, success
wait
等待页面加载
seconds (1-10)
ask_user
询问用户
question
click_element_by_index
按索引点击
index
input_text
输入文本
index, text
select_dropdown_option
选择下拉项
index, text
scroll
垂直滚动
down, num_pages, pixels, index
scroll_horizontally
水平滚动
right, pixels, index
还有一个实验性的 execute_javascript,需要显式开启。
MacroTool 模式:一次调用返回全部
这是架构上最精妙的设计。Agent 不是让 LLM 逐个调用工具,而是把 所有工具打包成一个 AgentOutput 宏工具:
{
"evaluation_previous_goal": "成功点击了登录按钮",
"memory": "已完成2/5步,下一步填写用户名",
"next_goal": "在用户名输入框中输入 admin",
"action": {
"input_text": { "index": 3, "text": "admin" }
}
}
每一步 LLM 必须同时输出:反思(evaluation)、记忆(memory)、下一步目标(next_goal)、具体操作(action)。这不是简单的 function calling,而是 ReAct 范式的完整实现。
normalizeResponse:容错到极致的响应解析
LLM 不靠谱是常态。normalizeResponse 函数用了 5 级渐进式修复 来处理各种奇葩返回:
修复优先级:
#1: tool_call 存在但 function.name 不是 AgentOutput → 包装成 action
#2: 没有 tool_call,但 content 里有 JSON → 解析为 AgentOutput
#3: 解析出的 JSON 带 type: "function" → 提取 arguments
#4: 解析出的 JSON 没有 action 字段 → 整体包装为 action
#5: 以上全部失败 → 回退到 wait 1 秒(不崩溃!)
最后那个 #5 是关键——永远不 crash,最差也只是等一秒钟。这就是工程品味。
主循环:observe → think → act
for (;;) {
1. 观察 → getBrowserState() → 获取当前页面文本表示
2. 注入观察结果 → handleObservations() → 警告剩余步数等
3. 组装 prompt → system prompt + 历史 + 当前页面
4. 调用 LLM → invoke() → 获取结构化响应
5. 执行动作 → 调用对应工具
6. 记录历史 → 存入 history 数组
7. 检查终止条件 → done / maxSteps / error
}
每步之间有 0.4 秒的冷却期,既防止 API 限流,也给页面足够的渲染时间。
Layer 4:UI 面板层——给 Agent 一张脸
整个 UI 是纯 DOM 操作构建的——没有 React,没有 Vue,没有 Shadow DOM。一个 Panel 类管理所有状态:
- 状态指示器:idle → thinking → executing → completed/error,每种状态对应不同的 CSS 动画
- 历史面板:可展开/收起,自动滚动到底部
- 任务输入框:支持中文输入法(监听
isComposing防止回车误触) - 国际化:内置
en-US和zh-CN两套翻译,通过I18n类统一管理
状态文本动画
值得一提的是 header 状态文本的更新用了一个 450ms 的轮询 + 淡入淡出动画:
检测到新状态 → fadeOut(150ms) → 更新文本 → fadeIn(300ms)
防止了快速连续更新导致的闪烁,用户体验上的细节功夫。
Layer 5:WebGL 渲染层——最后的视觉惊叹
这一层是整个框架里最意想不到的部分:它包含了一个 完整的 WebGL2 着色器程序,用来渲染 Agent 运行时的边框发光效果。
Fragment Shader 解析
// 四个光点沿边框旋转,速度和半径各不相同
const vec4 speeds = vec4(-1.9, -1.9, -1.5, 2.1);
// SDF(有符号距离场)计算圆角矩形
float dBorderBox = sdRoundedBox(centeredPos, halfSize, uBorderRadius);
// 内发光 + 暗角 + 噪声 = 会呼吸的边框
float glow = getInnerGlow(...);
glow *= getVignette(uv);
glow *= random(pos + uTime) * 0.1 + 1.0;
四种颜色(蓝、紫、橙、黄)的光点以不同速度绕边框旋转,配合 breath 呼吸效果和随机噪声,创造出一种"活着的"视觉感。
还有一个滑动光标——通过 requestAnimationFrame 实现的缓动指针,跟随 AI 的操作在页面上移动。移动使用了 0.2 的线性插值系数,所以光标是"滑"过去的,不是"跳"过去的。
Demo 模式与扩展配置
控制台注入(尝鲜模式)
Demo 脚本内置了默认配置:
const DEMO_MODEL = "qwen3.5-plus";
const DEMO_BASE_URL = "https://page-ag-testing-ohftxirgbn.cn-shanghai.fcapp.run";
const DEMO_API_KEY = "NA";
Demo 版本连接的是阿里云函数计算上的代理服务,使用通义千问 3.5 Plus 模型。API Key 为 "NA",因为代理服务端已内置鉴权。
Chrome 扩展(推荐方式)
更优雅的使用方式是安装 Page Agent Ext 扩展。配置项包括:
- Base URL:填入兼容 OpenAI 的 API 地址(如阿里云 DashScope 的
https://dashscope.aliyuncs.com/compatible-mode/v1) - Model:选择模型(如
qwen3.5-plus) - API Key:你自己的 API Key
- Language:支持中文/英文切换
配置完成后,在任意网页点击扩展图标,输入自然语言指令即可。比如"帮我点赞这些文章"——Agent 就会自动识别页面上的点赞按钮,逐个点击。
设计哲学总结
分析完 3000+ 行代码,提炼出几个核心设计原则:
- 永不崩溃 —
normalizeResponse的 5 级容错、try/catch包裹的每一步、最终兜底的wait(1) - 像人一样操作 — 完整的事件序列、原生 setter 绕过框架、模拟反应时间
- 最小化 Token — DOM → 简化文本的压缩率极高,属性自动去重、文本裁截
- 分层独立 — 每层都可以单独替换,PageController 和 Agent 解耦,UI 和逻辑分离
- 渐进增强 — Demo 模式开箱即用,高级用户可自定义模型、工具、prompt
最后说回那四行代码。 你往控制台粘贴的每一个字符,都是在加载一个精心设计的微型操作系统。它有大脑(LLM 调度)、有眼睛(DOM 感知)、有手(交互操作)、有嘴(UI 面板)、甚至有装饰(WebGL 发光)。
这就是现代 Web AI Agent 的真实面目——不是一个简单的 ChatBot,而是一个会看、会想、会操作的数字生命体。