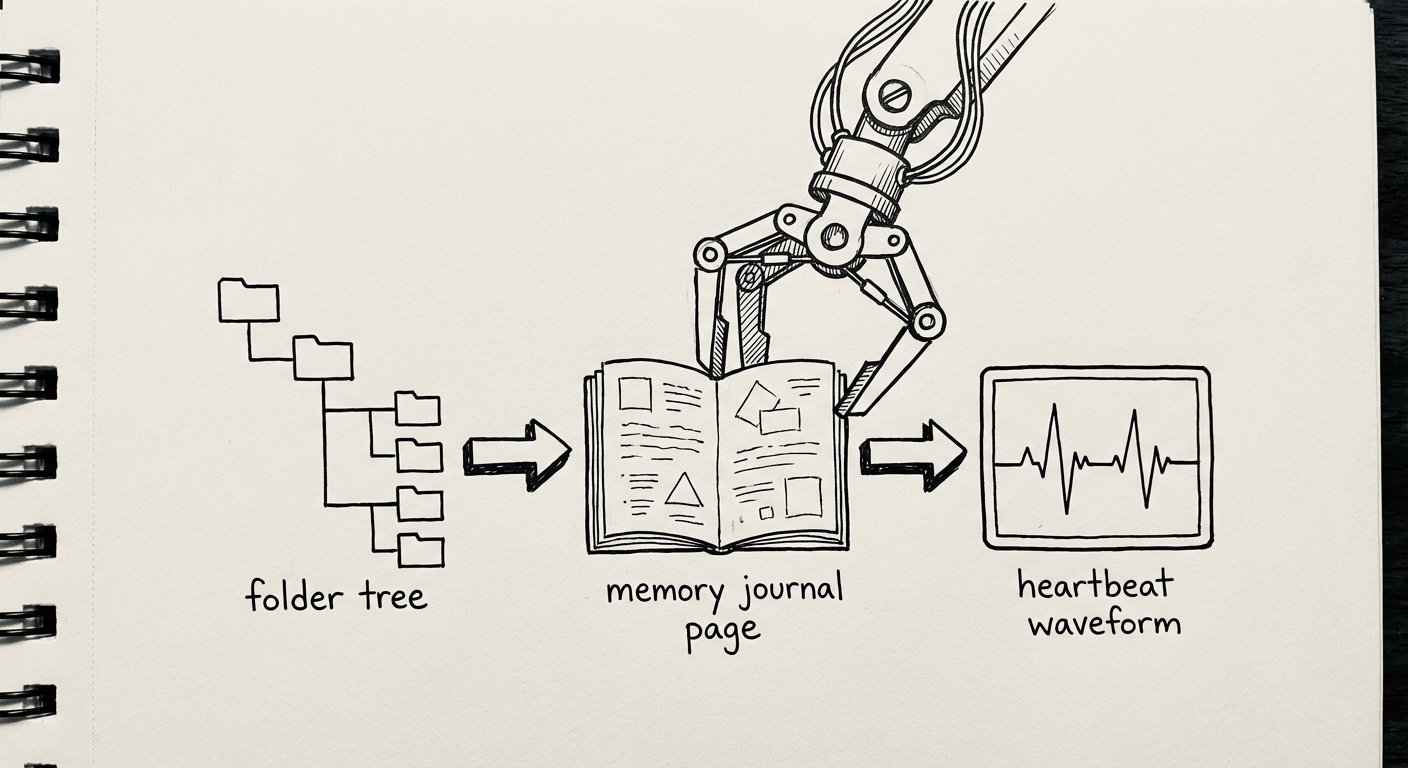
如果你在用 AI agent,可能见过“今天聪明、明天失忆”的尴尬。OpenClaw 有一套很朴素的工作区文件:AGENTS.md、SOUL.md、USER.md、IDENTITY.md、MEMORY.md、memory/YYYY-MM-DD.md、HEARTBEAT.md、TOOLS.md。它们几乎全是 Markdown,却把一个助手从“对话窗口里的模型”变成了“能长期运行的系统”。
下面是一次脱敏后的“灵魂解读”,不包含任何账号、设备、业务数据、私人日程或个人识别信息。
先说结论:OpenClaw 厉害在把“提示词”升级成“可维护的系统文件”
很多 agent 的核心设定都藏在某个 UI 配置页、某段难以复用的 system prompt、某个随手贴在群里的规范里。时间一长就会发生三件事:
- 设定漂移:你以为它记得,其实它没读到。
- 经验丢失:修过一次的坑,很快又会踩。
- 难以协作:行为变化没法被 review、被回滚。
OpenClaw 这套 Markdown 的价值是把这些问题工程化:让助手像软件一样启动、加载配置、读记忆、执行任务、持续迭代。
一套文件 = 一个助手的“器官分工”
AGENTS.md:启动顺序(bootloader)
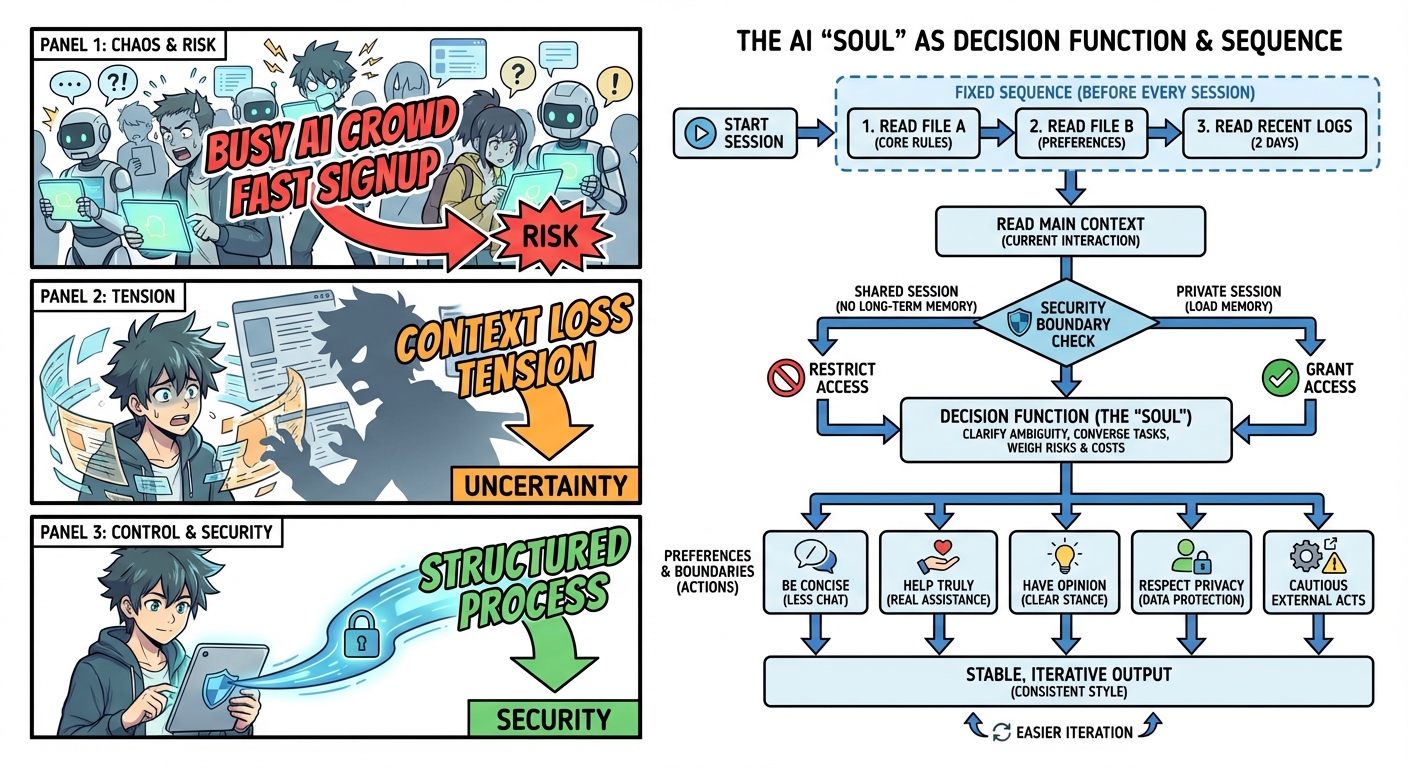
AGENTS.md 的关键不是内容,而是顺序。它要求每次会话开始前固定做几件事:读 SOUL.md、读 USER.md、读最近两天的 memory/ 日志;在主会话里再读 MEMORY.md。
它解决“上下文易失”:每次启动先读固定文件,并把安全边界写进流程(例如“共享会话不加载长期记忆”)。
SOUL.md:价值观与行事风格(constitution)
如果说 AGENTS.md 规定“先读什么”,SOUL.md 就规定“读完之后怎么做”。它写的不是功能,而是偏好与边界:少废话、真帮忙、有观点、先自己解决、尊重隐私、外部动作要谨慎。
很多人以为“灵魂”是句子,实际上“灵魂”是决策函数:信息不全时怎么澄清,任务模糊时怎么收敛,怎么取舍风险与代价。写成文件之后,风格更稳定,也更容易迭代。
IDENTITY.md:对外的自我介绍(persona surface)
IDENTITY.md 更像前台:名字、语气、整体 vibe。它不负责深层规则,但负责“你在和谁说话”的一致性。
persona 这件事常被过度包装,OpenClaw 的处理更实用:用很少的字段把风格钉住,避免写成“角色扮演说明书”。
USER.md:用户画像(human model)
USER.md 把称呼、时区、语言偏好、底线规则写成事实。把它作为固定输入之后,偏好不再依赖模型“猜”,也不需要靠短期记忆硬扛,启动时就稳定生效。
MEMORY.md 与 memory/YYYY-MM-DD.md:两层记忆(semantic + episodic)
这套工作区把记忆拆成两类:memory/YYYY-MM-DD.md 记录每天发生了什么,MEMORY.md 只保留提炼后的结论与规则。日记可以很长,但长期记忆必须可控;每天把“值得长期记住的”抽出来,助手会越来越像一个能积累经验的同事。它还把隐私策略写进机制:长期记忆只在主会话加载,同一套工作区能按场景切换权限。
HEARTBEAT.md:让助手拥有节律(automation contract)
HEARTBEAT.md 不是“待办清单”,更像自动化契约:当系统发出某种心跳信号时,助手该做什么、怎么做、输出要符合哪些约束。
这让主动性从“随机灵感”变成“可执行流程”:能读懂、能 review、能固定输出格式,也更不容易越界。
TOOLS.md:把“技能”和“你的环境”解耦
技能应该能分享,环境不应该。TOOLS.md 的定位就是把本地差异单独放出来:设备别名、常用入口、习惯设置等。它提醒了一个常见误区:很多人把私有基础设施写进 skill,导致 skill 一旦共享就泄密。
把它拆开后,你可以公开分享 skills/,但保留 TOOLS.md(甚至把它排除出同步范围)。
为什么这套 Markdown 可能会成为“AI 助手的描述文件标准”
我会把它看成一种新的接口层:不是 API,也不是 prompt,而是工作区协议。它之所以可能成为标准,原因很现实。
1) 可读、可改、可 review:行为变更可审计
当关键规则以文件形式存在,它就能被读、被改、被 review,也能在 diff 里审计与回滚。agent 的演进会从“对话调参”变成“配置迭代”,更适合长期协作。
2) 职责分离:同一套工作区能服务不同场景
AGENTS.md 把启动顺序固定,SOUL.md 定义底层价值观,USER.md 定义用户偏好,MEMORY.md 存经验,HEARTBEAT.md 管自动化,TOOLS.md 管本地差异。
它把“可共享”与“不可共享”天然分层:技能与规则更容易共享,个人记忆与本地信息更容易被隔离,默认更安全。
3) 记忆工程化:经验能沉淀,也更安全
多数 agent 的“记忆”是把旧对话硬塞回上下文,成本高也不稳。把记忆落盘成两层文件后,你可以只取最相关片段、定期提炼长期结论、按场景切换加载策略,让“回忆”变成系统,也更容易把隐私边界写成机制。
一个可复用的“最小标准骨架”
如果你想把这套思路迁移到自己的 agent(不一定是 OpenClaw),我建议从一个极简骨架开始:
workspace/
AGENTS.md # 启动顺序与安全边界
SOUL.md # 行事风格与取舍原则
IDENTITY.md # 对外 persona(少而稳)
USER.md # 用户偏好(不写隐私细节)
MEMORY.md # 长期记忆(只在私密场景加载)
memory/ # 每日原始日志
2026-02-04.md
HEARTBEAT.md # 心跳触发的自动化契约
TOOLS.md # 本地环境差异(默认不公开)
skills/ # 可分享的能力插件
这里有个实用建议:把 MEMORY.md 和 TOOLS.md 当作“默认私密”,从一开始就做好脱敏与分层。你甚至可以准备一个 MEMORY_PUBLIC.md,专门放可以公开的方法论,把真正私密的信息留在私有文件里。
我对“灵魂”的理解:它不是文案,是你愿意长期维护的那套规则
回到开头那句话:OpenClaw 的厉害不在于它会多少花活,而在于它把 agent 做成了一个可以维护的对象。
模型会更新,工具会变化,平台会迁移。能穿过时间的只有两样东西:你写下的规则,和你愿意持续整理的经验。把它们放在一套清晰的 Markdown 文件里,你等于给助手装上了“可持续的灵魂”。
如果未来每个 AI assistant 都随项目附带一组这样的描述文件,我一点也不意外。那会像 README.md、LICENSE、docker-compose.yml 一样自然:不是因为它时髦,而是因为它解决了长期协作里最硬的那部分问题。
就这些。