你最近要是多刷了几天抖音、快手或者 B 站,大概率见过这种内容:几张动漫质感很强的画面,角色颜值在线,剧情一句接一句往前推,配上旁白、配音和音乐,几分钟就能把一个悬疑、甜宠、修仙或者逆袭故事讲完。很多人第一反应是:这不就是 AI 一键生成的吗?再往下看,评论区又全是黑话——“这镜抽卡抽了半小时”“角色还是漂了”“先训个 LoRA 再说”。
外行听着像玄学,做过的人知道,这里面一点也不玄。AI 漫剧不是一句 prompt 换来一条成片,它更像一条内容生产流水线:前面是编剧和分镜,后面是出图、修图、图生视频、配音、剪辑,中间夹着一堆重复劳动和返工。真正把账号做起来的人,拼的也不是谁更会写华丽提示词,而是谁更早把这件事从“碰运气”做成“有流程”。
这篇文章就聊透三件事:AI 漫剧到底是怎么做出来的;大家老说的“抽卡”究竟是什么意思;还有最关键的——主角怎么才能不变脸,形象怎么才能稳住。
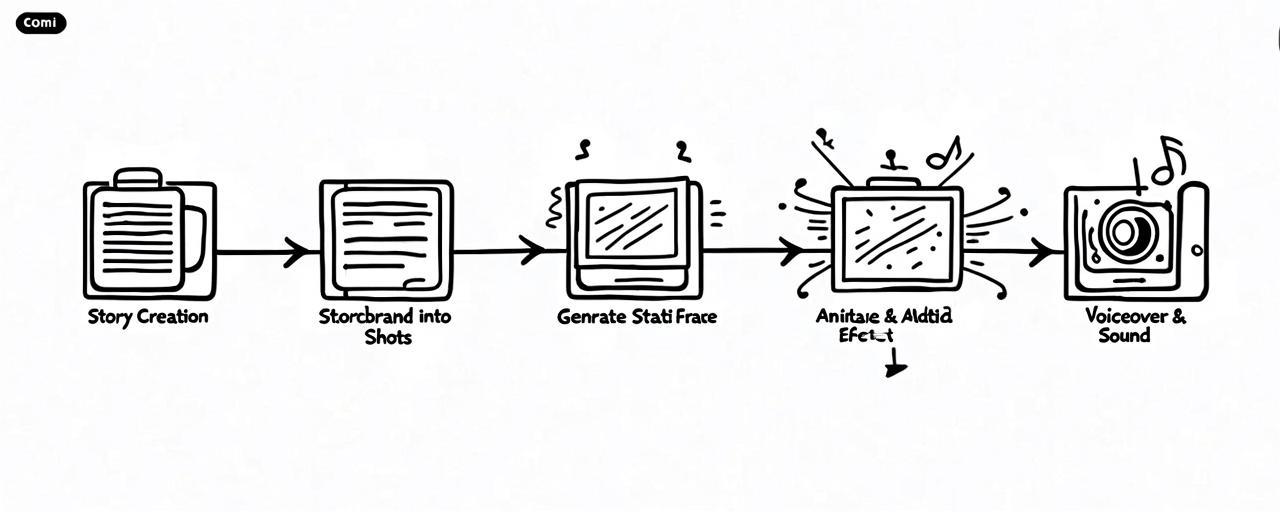
AI 漫剧本质上不是动画工业,而是“图像流水线 + 轻视频包装”
先把一个误解打掉。大多数 AI 漫剧,并不是传统意义上的动画。它没有那么多逐帧原画,也没有完整的动作中间张。更准确的说法是:它是一种介于漫画分镜、动态海报和短视频叙事之间的新形态内容。
它的底层结构通常是这样的:先有故事,再把故事拆成镜头;每个镜头生成一张或者一组静态画面;再用图生视频、首尾帧补间、镜头推拉、局部动效把画面“轻轻推起来”;最后配上人声、环境音、字幕和剪辑节奏。你看到的是“会动的动漫短剧”,但生产侧真正稳定可控的部分,仍然是静态图。
这也是为什么很多 AI 漫剧明明画面不错,可一到大动作就容易崩。因为它的强项从来不是复杂演出,而是用低成本把连续镜头组织起来,让人愿意一条接一条看下去。说白了,它更像是内容工业的一次重组:把原来动画团队里最重的人力环节,用模型和流程替掉一部分。
一条完整的 AI 漫剧生产链,一般分七步
1. 先定题材,再定节奏,不要一上来就生图
很多新手的第一反应是打开 Midjourney、即梦或者 Stable Diffusion,先画一张主角海报。这样当然有快感,但通常也就止步于“有一张图”。真正能做成系列的账号,第一步一定不是画图,而是选题。
因为短视频平台对漫剧的要求很现实:开头几秒要有钩子,剧情推进要快,人物关系要清楚,情绪要能立住。题材也相对集中,悬疑反转、豪门虐恋、逆袭复仇、古风修仙、都市异能,翻来覆去就这些,但每个赛道都有固定的观众预期。你要先知道自己在讲什么,再决定它该长成什么样。
这一步通常会产出几个东西:一句话梗概、人物关系、核心冲突、每集节奏点、每个镜头的情绪目标。做得更细一点,还会直接把文案拆成镜头脚本。镜头脚本不是文学写作,它更像给机器看的施工图:谁在画面里,站在哪里,什么表情,什么动作,景别是近景还是远景,镜头要推还是拉,台词在哪个点落下来。

2. 剧本拆分镜,把“故事语言”翻译成“视觉语言”
这一步非常关键,也是很多人低估的一步。AI 模型并不理解“这个角色经历了巨大的心理转折”这种抽象叙事。你得把它翻译成可以被看见的东西,比如“男人站在门口停住脚步,右手还握着门把,视线越过客厅,看到已经收拾好的行李箱,神情从愤怒转成迟疑,室内冷色调,逆光”。
一个成熟的 AI 漫剧团队,往往会把剧本拆成带字段的表格。常见字段包括:镜头号、时长、景别、机位、场景、人物、动作、表情、光线、关键词、台词、音效。这看起来土,但极其有用。后面无论你是喂给大模型重写 prompt,还是喂给出图模型直接生成画面,都会稳定很多。
说得再直白一点:AI 漫剧做得顺不顺,很多时候不是输在画质,而是输在拆镜头时太糙。文字写得像小说,镜头却没法执行,后面就只能靠抽卡硬补。
3. 角色设定先资产化,不然主角一定会漂
AI 漫剧里最容易翻车的,不是背景,不是特效,而是人脸。第一张图很好看,第二张勉强像,第三张已经认不出来了——这事几乎每个新手都踩过。
原因很简单。对大多数模型来说,人物不是一个“稳定角色”,而是一组概率分布。你每次重新生成,它都在根据提示词重新猜一遍“这个人可能长什么样”。你如果只是反复写“黑发少年、蓝色眼睛、眼角有痣、穿黑色风衣”,模型当然可能画出相似的人,但它不会真的记住你上一次那张脸。
所以在实操里,主角必须先做成“角色资产”,而不是一句描述。最基础的配置,是给每个主要角色做一份角色卡:年龄感、身材、脸型、发型、发色、瞳色、常穿服装、标志物、常见表情。更稳一点的做法,是做三视图或者多角度角色图:正面、侧面、四分之三侧、半身、全身,最好再补一组不同情绪版本。
你可以把这一步理解成:先把主角从一句话,变成一个文件夹。后面每个镜头都不是从零开始猜,而是围绕这个文件夹往外扩。
4. 静帧生产才是真正的主战场
很多外行看到“AI 视频”这几个字,会以为关键在视频模型。其实对大多数漫剧账号来说,真正决定成片质感的,还是静帧。静帧稳,后面怎么动都好办;静帧不稳,后面所有图生视频都只是把错误放大。
这一阶段最常见的工具组合大概分三类。
第一类是轻量路线。比如用即梦、豆包、可灵一类平台,优点是上手快,不需要自己搭环境,中文理解也比较友好。缺点是参数控制没那么细,批量一致性一般。
第二类是 Midjourney 路线。它的长处是画质高、风格统一、成图快,做角色打样和封面尤其强。很多创作者会先用 Midjourney 把角色和关键场景打出来,再把图拿去别的工具做图生视频。
第三类是 Stable Diffusion / ComfyUI 路线。它更重,但控制力最强。你可以接 LoRA、IP-Adapter、ControlNet、局部重绘、批量工作流,适合想做系列化内容的人。
无论哪条路,静帧生产都不是“一次生成一张图”这么简单。更真实的生产方式是:一镜多出、筛图、回修、定稿。很多镜头你会一次出四张、八张甚至十六张,从里边挑一张脸最稳、动作最顺、服装没丢的。选出来之后,可能还要局部重绘一下眼睛、手、耳饰或者衣服褶皱。到这里,所谓“AI 一键出片”的幻觉基本就没了。
5. 让画面动起来,通常不是靠大动作,而是靠小动效
到了图生视频阶段,很多人又会犯一个错误:总想让角色做很复杂的动作。跑、跳、打斗、翻身、回头、挥手、镜头跟拍,全往里塞。结果往往是,动作越大,脸越漂,肢体越乱,衣服和背景一起崩。
这不是你不会写 prompt,而是当前不少模型的稳定区间就这么大。真正好用的思路是先接受现实:AI 漫剧最稳的镜头语言,不是复杂演出,而是轻微动态。头发轻轻动一下,衣摆飘一下,镜头缓慢推进,视线从左移到右,嘴唇小范围开合,背景加一点烟雾和光影变化。这样做看似“没那么炫”,但成片稳定,更新效率也高。
所以很多成熟账号的镜头处理其实很克制。它们知道什么时候该用图生视频,什么时候只用运镜,什么时候干脆停在一张高质量特写上,让配音和台词去带戏。别小看这点克制,很多时候它决定的是产能,而不是审美。
6. 配音、音效和字幕,决定成片有没有“戏”
AI 漫剧另一个常被忽略的地方,是声音。很多画面看起来不差,但一配上机械 TTS,味道立刻就散了。因为漫剧本质上不是纯视觉内容,它的推进很大程度靠的是声音节奏。
通常会有三层:角色对白、旁白、环境音。对白负责立住人物,旁白负责交代信息,环境音负责氛围。预算高一点会做多人音色区分,预算低一点至少也会把男女主和旁白分开。再往上走,还会给不同角色固定音色模板,让观众听几集之后形成记忆。
字幕也一样。别把它当配件。短视频里的漫剧,很多人是半静音看的,字幕承担的信息量不小。字体、断句、卡点、颜色层级,都在影响留存。
7. 最后才是剪辑和封装
真正到剪辑阶段,技术上反而没那么难,难的是判断。哪一镜要快切,哪一镜该留白,哪句台词该先出,哪段旁白该删,哪里要故意停顿一下吊观众胃口。这个阶段更像内容编辑,而不是技术操作。
AI 漫剧跑起来之后,最容易让人上头的不是“我又学会了一个新模型”,而是“我终于能把一条内容从脚本一路推到发布”。那种感觉很像搭工厂。前面任何一个环节没搭顺,后面都会卡住。
“抽卡”到底是什么,为什么大家老在说
现在说回那个高频黑话:抽卡。
如果你是从手游圈来的,这个词不难理解。放在 AI 生图和 AI 漫剧里,它通常指的就是:在模型带随机性的前提下,反复生成、反复筛选,像抽卡一样去“赌”一张满意的结果。
这词在圈里有两层意思。
第一层,也是最常见的一层,就是刷图挑图。你想要一个镜头:男主在雨夜回头,眼神有点狠,衣服被打湿,背景是霓虹反光。你一轮生成四张,可能只有一张神态对,两张脸不太像,一张手崩了。那你就继续重抽,换 seed,微调提示词,或者把参考图再喂进去一次。最后终于出一张能用的,大家就会说“这次出货了”。这就是抽卡。
第二层,是提示词抽卡。现在也有一些工具会把风格词、镜头词、人物词、服装词做成可视化标签,用户每次随机抽几个出来拼 prompt。这种玩法更偏灵感生成,带点游戏化。它适合找风格、找方向,不太适合做严肃的连续内容。
为什么大家老说抽卡?因为在很多工具里,随机性依然很大。尤其你没有建立角色资产、没有固定参数、没有参考图约束时,模型每次都像在重新猜题。你不抽,就很难碰到那张“对的图”。
但问题也在这里。抽卡适合做单图,不适合做产线。你偶尔抽中一张神图没什么难度,难的是连着二十个镜头都能维持同一个人、同一种世界观、同一套审美。这个时候,单纯靠抽卡就不够了。
主角形象一致性,核心不是 prompt,而是工程化约束
这是全文最重要的一部分。
很多教程喜欢把角色一致性说成“提示词技巧”,仿佛只要你把人物描述写得更长、更细、更华丽,模型就会乖乖照做。现实没有这么温柔。你提示词写得再长,也只能增加命中率,不能从根上解决角色漂移。
真正在生产里管用的,是一套工程化约束。简单讲,就是别让模型每次自由发挥,而是给它越来越多的边界。
第一层边界,是固定角色特征。这个上面已经讲过了,角色卡、三视图、情绪图、服装图,这些都属于基础资产。你越早做,后面越省时间。
第二层边界,是固定参考图。很多创作者会选一张最稳定的“母图”,把它当成所有镜头的核心参考。后续无论换场景、换镜头、换动作,先想办法保证“这个人还是从这张图长出来的”。
第三层边界,是固定模型和参数。别今天用一个模型,明天换一个底模,后天再加新风格词,然后指望角色还能稳。模型、LoRA 权重、分辨率、采样器、步数、CFG、种子区间,这些一旦来回乱动,角色就很容易跑偏。很多所谓“主角变脸”,其实不是 AI 无能,而是流程太飘。
第四层边界,是参考控制。Midjourney 这类工具有角色参考思路,Stable Diffusion / ComfyUI 体系里更常见的是 LoRA、IP-Adapter、ControlNet 一起上。你可以把它们理解成不同层次的“拴绳子”:LoRA 负责让模型学会这个角色,IP-Adapter 负责每次生成前再给模型看一眼,ControlNet 则负责别把姿态和构图跑飞。
第五层边界,是后期回修。很多人不愿意承认这件事,总觉得用了 AI 就该一步到位。真相是,成熟团队几乎都会修。修眼睛,修脸,修手,修饰品,修衣服,修背景穿帮。AI 负责把 70 分推到 85 分,最后那 10 分到 15 分,很多时候还是得靠人工把它压过去。
说到底,角色一致性的关键不是“如何一次生成完美主角”,而是“如何让主角在一百次生成里都尽量别走样”。这两件事,思路完全不同。
如果只做个人号,什么流程最现实
不是每个人都要一上来训练 LoRA、搭 ComfyUI、搞自动化节点。真没必要。你如果是个人起号,最现实的做法是分阶段。
第一阶段,先验证题材。用大模型把故事拆成十到二十个镜头,先做一条一分钟以内的短内容。工具可以尽量轻:豆包或者其他大模型负责拆文案,即梦或者 Midjourney 负责出图,可灵或者 Runway 负责轻动效,剪映负责剪辑和字幕。这一阶段别追求系统最强,先看自己能不能把一条内容完整做出来。
第二阶段,开始做角色库。选出主角最稳定的一版,补齐正面、侧面、半身、全身,再建立固定 prompt 模板和固定服装设定。你会明显发现,返工开始下降,抽卡时间也会缩短。
第三阶段,再考虑进阶技术。比如训练角色 LoRA,把常用镜头做成 ComfyUI 工作流,把批量命名、素材归档、字幕模板、音色模板都固定下来。到了这一步,你就不是在“做几条视频”,而是在搭一个能持续出货的内容系统。
这三个阶段别倒着来。很多人一开始就沉迷工具细节,节点图堆得很大,结果一条能发的成片都没做出来。那就本末倒置了。
AI 漫剧最常见的五个坑
第一个坑,是把剧本当 prompt。故事写得很热闹,镜头执行不了,最后生成出来全是废图。
第二个坑,是角色设定没做完就着急开工。第一集还能勉强糊过去,第二集开始人物就越来越不像,等想补救时,前面几十张图已经和后面接不上了。
第三个坑,是过分迷信大动作。动作越大,镜头越炫,崩坏概率越高。AI 漫剧这条路,很多时候赢在克制。
第四个坑,是参数不固定。今天换模型、明天换风格、后天换提示词模板,最后全流程没有一个稳定基线,只能一直抽卡。
第五个坑,是忽略素材管理。真做起来你就会发现,一个项目很快会堆出几百张图、几十个视频片段、好几版音频和字幕。没有命名规则、没有文件夹结构、没有版本区分,后面回头找素材会把人逼疯。
这门生意最后拼的,不是模型,而是“稳”
聊到这里,其实可以把 AI 漫剧这件事看得更清楚一点:它不是一个单点工具问题,而是一个流程问题。谁的工具更新得快,不一定谁赢;谁能把角色稳定住、镜头拆清楚、素材管明白、更新节奏跑顺,谁反而更有机会把账号做起来。
这也是为什么业内越来越少有人迷信“神 prompt”了。大家最后都会走向同一个方向:角色资产化、镜头模板化、参数固定化、后期流程化。你不一定非要把系统做得多重,但必须让每一步都尽量可重复。
说得再直白一点,AI 漫剧的上限当然看模型,可下限全在流程。流程一乱,再强的模型也救不了你;流程一稳,哪怕用的不是最贵那套工具,也能持续出能看的内容。
最后给一个实用判断:你是在做作品,还是在赌运气
如果你现在做 AI 漫剧,经常出现下面这些情况:一张图很好看,但下一张接不上;今天出货很多,明天一张都不满意;主角每次都像双胞胎不是同一个人;做一条片子花大量时间在“重来一遍”——那八成说明你还在抽卡阶段。
抽卡本身没什么丢人的,谁都是从这一步过来的。问题只在于,你准备停在这里,还是准备往前走半步,把它变成流程。
真正的分水岭,不是你会不会用某个模型,而是你有没有意识到:主角一致性不是写出来的,是管出来的;AI 漫剧不是一键生成的,是一段一段搭出来的。
当你开始把角色当资产、把镜头当模板、把参数当基线、把回修当质检,很多原来看上去很玄的东西,突然就不玄了。所谓“抽卡”,也会从唯一办法,慢慢变成只是偶尔补运气的一环。
这才是 AI 漫剧真正能跑起来的起点。不是更会许愿,而是更会施工。