过去一周,AI Agent 圈一口气出了五个"记忆"相关开源项目。腾讯、盛大、字节、矩阵起源、上海交大联合,都在抢同一个心智位——「让 Agent 不再是金鱼脑」。
我把五个项目都摸了一遍,包括论文、第三方解读、工程实测。结论一句话:五个方案根本不在同一层。把它们当作竞品对比,是营销造出来的幻觉。
下面这篇,我从模型层往上一直讲到数据治理层,告诉你哪个场景该用哪一层。最后还有一个反共识发现:很多人花大力气调高级调度算法,不如先把事实提取做扎实。
五个项目,五个层级
先把全景给你:
- 模型层 — MSA(EverMind-AI):稀疏注意力 + 文档级 RoPE,把上下文推到 1 亿 token
- 调度层 — MemOS(MemTensor):把记忆当 OS 资源,统一明文/激活/参数三种形态
- 语义层 — EverMemOS(EverMind-AI):MemCell 三元结构,脑科学 engram 启发
- 任务符号层 — TencentDB Agent Memory(腾讯):Mermaid 画布 + 上下文卸载
- 数据治理层 — Memoria(矩阵起源):Git 式版本控制 + Copy-on-Write
注意 MSA 和 EverMemOS 来自同一家盛大旗下的 EverMind-AI 团队。这件事本身就在告诉你:单一层级解决不了 Agent Memory 的全部问题,他们自己也得拆成两个项目。
MSA:把上下文容量推到 1 亿
MSA 的全名是 Memory Sparse Attention。它解决的是一个非常具体的问题:全注意力 O(L²) 让主流 LLM 的有效上下文长度卡在 128K-1M。
它的三件套:
- 可扩展稀疏注意力 + 文档级 RoPE,把复杂度压到 O(L)
- KV 缓存压缩 + 记忆并行,2×A800 跑通 1 亿 token
- 记忆交织(Memory Interleaving)支持跨文档多跳推理
关键数字:RULER NIAH 在 100 万 token 上 MSA 拿到 94.84% 准确率,同骨干 Qwen3-4B 在同长度直接崩塌到 24.69%。从 16K 外推到 1 亿 token,性能下降不到 9%。
模型 MSA-4B 已经在 HuggingFace 开源。这是个模型层方案——你换不动算子,但你可以直接用它的 checkpoint。
MemOS:把记忆当成 OS 资源
MemOS 来自上海交大/浙大/北邮联合的 MemTensor 团队,39 位作者。它的核心抽象是 MemCube:
MemCube = {
Payload: 明文 | 激活态(KV-Cache) | 参数增量(LoRA),
Metadata: { 时间戳 / 权限 / 版本 / 访问频率 / 过期时间 }
}
这个抽象的精妙之处是统一了三种记忆形态。同一条记忆,可以以明文存在数据库、以 KV-Cache 存在显存、或者烧成 LoRA 进模型参数。MemScheduler 自动判断该用哪种:
- 高频查询 → KV-Cache(TTFT 降 91.4%)
- 程序化技能 → 参数固化
- 临时事实 → 明文
记忆按 L0→L3 演化:原始数据 → 结构化自然语言 → 参数微调 → 世界模型与晶体化技能。基准上 LOCOMO 拿到 75.80,比 OpenAI Memory 高 43.7%。
MemOS 真正的稀缺价值不是性能,是治理维度。每个 MemCube 强制带审计、权限、TTL、版本——这是企业级 Agent 落地医疗/法律/金融的硬门槛,传统 RAG 完全没有。
EverMemOS:脑科学启发的语义记忆
陈天桥 + 邓亚峰主导,EverMind-AI 团队 4 个月做出来的。和 MSA 是兄弟项目。
它最有意思的设计叫 MemCell,是个三元结构:
- Episode:第三人称叙述,保留事件背景
- AtomicFact:离散可验证陈述句,支持精确匹配和冲突检测
- Foresight:带时间有效期的预测
Foresight 是我看下来最稀缺的一个设计。传统记忆系统把所有事实当永久真理,导致用户两天前的临时禁忌被永久外推。Foresight 给每条预测打上 start_time / end_time,比如「用户应避免酒精,有效期 Oct 20-Nov 3」——到时间自动失效。
EverMemOS 主张一句话:Agent 记忆的本质是「整合」,不是「检索」。所以它的检索叫 Reconstructive Recollection——不是 top-k 相似度,而是 MemScene 指导下的主动构造「必需且充分」的上下文。
LoCoMo 基准上 EverMemOS 拿 93.05%,次优 85.22%,Letta 74%,Mem0 68.5%,MemGPT 64.57%。差距不是工程优化能补的,是范式差。
TencentDB Agent Memory:符号化的任务记忆
腾讯这套定位明显不同。它不解长期人物画像,它解单次长任务的上下文爆炸。
核心三招:
- Mermaid 任务画布替代冗长日志,上下文里只留高密度结构图
- 完整工具日志卸载到
refs/*.md文件系统 - 基于
node_id的 grep 溯源——遇错直接下钻原文
WideSearch 基准上,OpenClaw 加这个插件,通过率从 33% 提到 50%,Token 消耗从 221.31M 降到 85.64M(省 61.38%)。SWE-bench 上 Token 也降 33%。
它的长期记忆走 L0 Conversation → L1 Atom → L2 Scenario → L3 Persona 四层金字塔,PersonaMem 准确率 48%→76%。
我个人觉得 Mermaid 画布是这个项目最锋利的洞见:用最少的符号表达最多的语义。LLM 精准理解,人类直接阅读,调试时还能 grep。
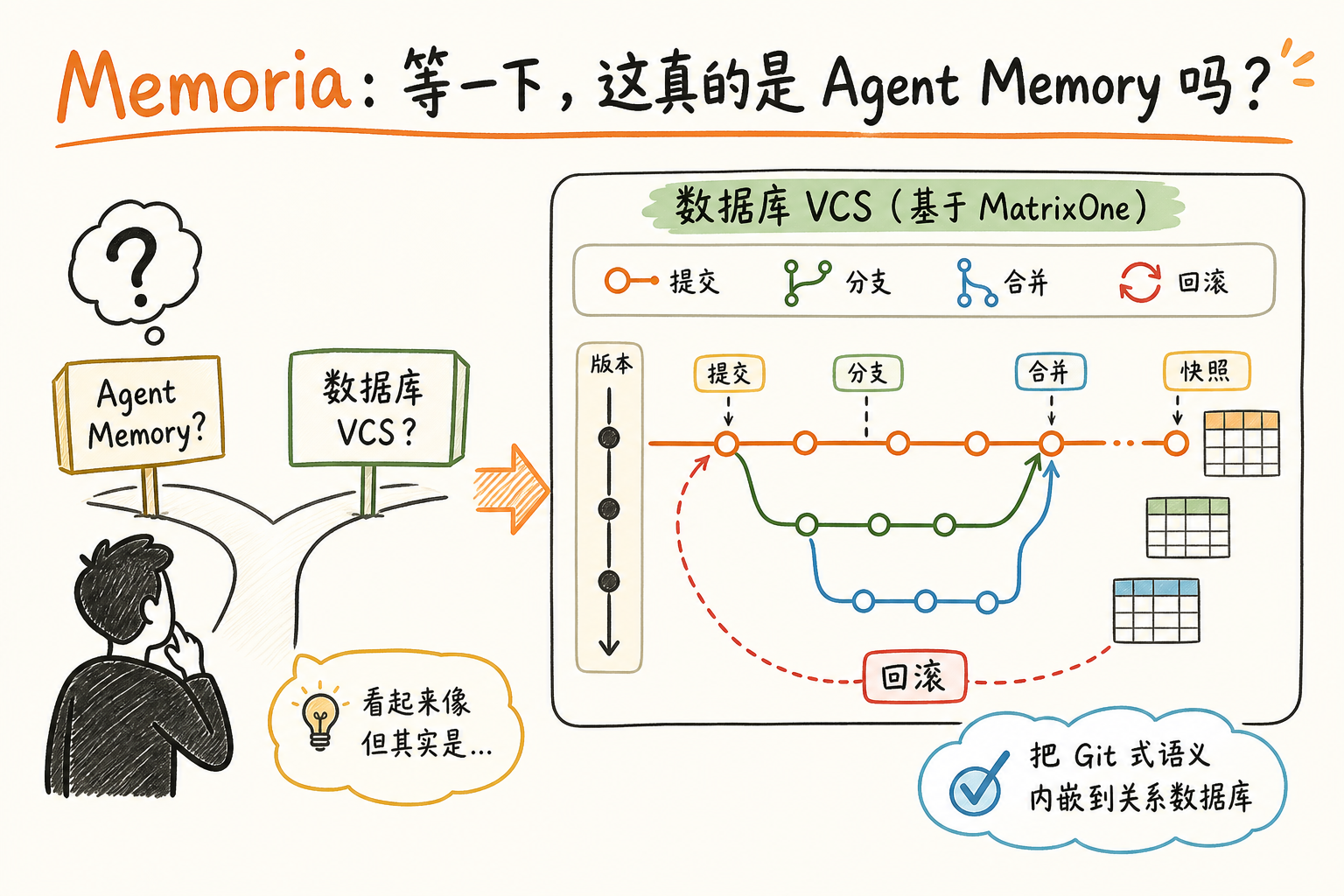
Memoria:等一下,这真的是 Agent Memory 吗?
矩阵起源 GTC 2026 发布的 Memoria,自称 "Git for Memory"。版本控制、快照、分支、合并、回滚——听起来是 Agent Memory 领域的稀缺能力。
我去翻它的 arXiv 论文(编号 2604.03927),发现一件有意思的事:论文标题是《Version Control System for Data with MatrixOne》。
直白说:这是一篇数据库 VCS 论文,不是 Agent Memory 论文。它的核心创新是把 Git 的 commit/branch/merge 语义原生嵌进关系数据库(基于 MatrixOne 的 MVCC + Copy-on-Write)。Agent Memory 是这个能力的衍生应用场景,被营销包装成了主线。
证据链:
- 论文实验跑的是 Clone 性能、Diff & Merge 冲突检测、协作工作负载
- 没有在 LoCoMo / LongMemEval 上测过
- 公开的真实生产案例缺失
我不是说 Memoria 没价值。版本化记忆这件事,EverMemOS / MemOS / TencentDB 都做不到。但你买它,得想清楚:你是想要一个 Agent Memory 框架,还是想要一个带 Git 语义的数据库。这两件事的工程边界、依赖体量、上手成本完全不一样。
Linus 会说:Don't break userspace, and don't lie about what your project is。
反共识:调高级算法之前,先把事实提取做扎实
如果你只读论文营销,会以为 Agent Memory 的胜负在于"分层结构有多复杂、调度算法有多聪明"。
有个独立工程师 Kevin 公开了一份 MemOS 实测博客。他在真实数据上把 F1 从 0.25 提到 0.56+。靠的不是上 L3 晶体化技能,也不是参数态记忆。靠的就两件事:
- 显式事实提取——把对话里的事实结构化抽出来
- 时间格式一致化——所有时间统一格式
Kevin 的结论很直白:论文里那些花哨的高级调度机制,在真实工程里收益有限。
这件事和 [TencentDB 团队的 Mermaid 画布]、[EverMemOS 团队的 AtomicFact] 都暗合:Agent Memory 的真正杠杆,是把信息结构化为可验证的最小单元。
剩下的调度、演化、召回,都是这个底子上的优化。底子不结实,再高级的调度也是花架子。
该怎么选?给你一个判断框架
按场景对号入座:
- 你想跑 1 亿 token 的长文档/法律案件/科研综述? 用 MSA,直接拉 MSA-4B 模型,但要接受 2×A800 的硬件门槛
- 你做企业级 Agent,要医疗/法律/金融合规? 用 MemOS,治理维度(审计/权限/TTL)是硬门槛
- 你做 to C 长对话产品(伴侣/客服/私人助理)? 用 EverMemOS,MemCell 三元 + Foresight 时间有效期是稀缺设计
- 你做 Coding Agent / 工具型 Agent,长任务上下文爆炸? 用 TencentDB Agent Memory,Mermaid 画布 + 上下文卸载是任务级最优解
- 你想要数据版本控制 + Agent Memory 副作用? Memoria 可以看,但别期待它替代上面任何一个
如果你硬要叠加用,模型层 MSA + 调度层 MemOS + 语义层 EverMemOS 在理论上不互斥。但生产环境我建议单点突破,不要拼装积木——三套依赖叠起来,Neo4j、Qdrant、Redis、Milvus、Elasticsearch、MongoDB 全开,运维成本会让你怀疑人生。
我的看法
Agent Memory 这个赛道,2025 年是平铺向量 RAG 的天下,2026 年彻底分层了。
值得关注的不是"哪家排行榜分高",是抽象本身在升级。MemCube 把记忆抽成 OS 资源,MemCell 把记忆抽成神经科学单元,Mermaid 画布把记忆抽成符号拓扑——这些抽象的差异,比任何一张基准跑分表都重要。
我个人最看好 EverMemOS 的 Foresight 时间有效期这个机制。不是因为它跑分高,是因为它把「记忆不应该都是永久真理」这件事第一次显式编码进了数据结构。其他系统多少都默认事实是永久的,然后靠后处理打补丁。
下一步该看什么?我会盯三件事:
- 跨 Agent / 跨框架的记忆互操作协议(MemOS 提的 MIP 是个起点)
- 晶体化技能这个概念能不能真的落地为可挂载的 LoRA 增量
- Mermaid 画布能不能成为 Agent 任务记忆的事实标准——这个赌得最大
剩下的,等真实生产案例堆够再回头看。